
This chapter dives into the history of the web itself: where it came from, and how the web and browsers have evolved to date. This history is not exhaustive;For example, there is nothing much about Standard Generalized Markup Language ( SGML) or other predecessors to HTML. (Except in this footnote!) the focus is the key events and ideas that led to the web, and the goals and motivations of its inventors.
An influential early exploration of how computers might revolutionize information is a 1945 essay by Vannevar Bush entitled “As We May Think”. This essay envisioned a machine called a memex that helps an individual human see and explore all the information in the world (see Figure 1). It was described in terms of the microfilm screen technology of the time, but its purpose and concept has some clear similarities to the web as we know it today, even if the user interface and technology details differ.
The web is, at its core, organized around the Memex-like goal of representing and displaying information, providing a way for humans to effectively learn and explore. The collective knowledge and wisdom of the species long ago exceeded the capacity of a single mind, organization, library, country, culture, group or language. However, while we as humans cannot possibly know even a tiny fraction of what it is possible to know, we can use technology to learn more efficiently than before, and, in particular, to quickly access information we need to learn, remember, or recall. Consider this imagined research session described by Vannevar Bush—one that is remarkably similar to how we sometimes use the web:
The owner of the memex, let us say, is interested in the origin and properties of the bow and arrow. […] He has dozens of possibly pertinent books and articles in his memex. First he runs through an encyclopedia, finds an interesting but sketchy article, leaves it projected. Next, in a history, he finds another pertinent item, and ties the two together. Thus he goes, building a trail of many items.
Computers, and the internet, allow us to process and store the information we want. But it is the web that helps us organize and find that information, that knowledge, making it useful.Google’s well-known mission statement to “organize the world’s information and make it universally accessible and useful” is almost exactly the same. This is not a coincidence—the search engine concept is inherently connected to the web, and was inspired by the design of the web and its antecedents.
“As We May Think” highlighted two features of the memex: information record lookup, and associations between related records. In fact, the essay emphasizes the importance of the latter—we learn by making previously unknown connections between known things:
When data of any sort are placed in storage, they are filed alphabetically or numerically. […] The human mind does not work that way. It operates by association.
By “association”, Bush meant a trail of thought leading from one record to the next via a human-curated link. He imagined not just a universal library, but a universal way to record the results of what we learn.
The concept of hypertext documents linked by hyperlinks was invented in 1964–65 by Project Xanadu, led by Ted Nelson.He was inspired by the long tradition of citation and criticism in academic and literary communities. The Project Xanadu research papers were heavily motivated by this use case. Hypertext is text that is marked up with hyperlinks to other text.A successor called the Hypertext Editing System was the first to introduce the back button, which all browsers now have. Since the system only had text, the “button” was itself text. Sound familiar? A web page is hypertext, and links between web pages are hyperlinks. The format for writing web pages is HTML and the protocol for loading web pages is HTTP, both of which abbreviations contain “HyperText”. See Figure 2 for an example of the early Hypertext Editing System.

Independently of Project Xanadu, the first hyperlink system appeared
for scrolling within a single document; it was later generalized to
linking between multiple documents. And just like those original
systems, the web has linking within documents as well as between them.
For example, the URL
http://browser.engineering/history.html#the-web-emerges
refers to a document called “history.html”, and
specifically to the element in it with the name
“the-web-emerges”: this section. Visiting that URL will
load this chapter and scroll to this section.
This work also formed and inspired one of the key parts of Douglas Engelbart’s mother of all demos, perhaps the most influential technology demonstration in the history of computing (see Figure 3). That demo not only showcased the key concepts of the web, but also introduced the computer mouse and graphical user interface, both of which are central components of a browser UI.That demo went beyond even this. There are some parts of it that have not yet been realized in any computer system. Watch it!

There is of course a very direct connection between this research and the document–URL–hyperlink setup of the web, which built on the hypertext idea and applied it in practice. The HyperTIES system, for example, had highlighted hyperlinks and was used to develop the world’s first electronically published academic journal, the 1988 issue of the Communications of the ACM. Tim Berners-Lee cites that 1988 issue as inspiration for the World Wide Web,Nowadays the World Wide Web is called just “the web”, or “the web ecosystem”—ecosystem being another way to capture the same concept as “World Wide”. The original wording lives on in the “www” in many website domain names. in which he joined the link concept with the availability of the internet, thus realizing many of the original goals of all this work from previous decades.Just as the web itself is a realization of previous ambitions and dreams, today we strive to realize the vision laid out by the web. (No, it’s not done yet!)
The word “hyperlink” may have been coined in 1987, in connection with the HyperCard system on Apple computers. This system was also one of the first, or perhaps the first, to introduce the concept of augmenting hypertext with scripts that handle user events like clicks and perform actions that enhance the UI—just like JavaScript on a web page! It also had graphical UI elements, not just text, unlike most predecessors.
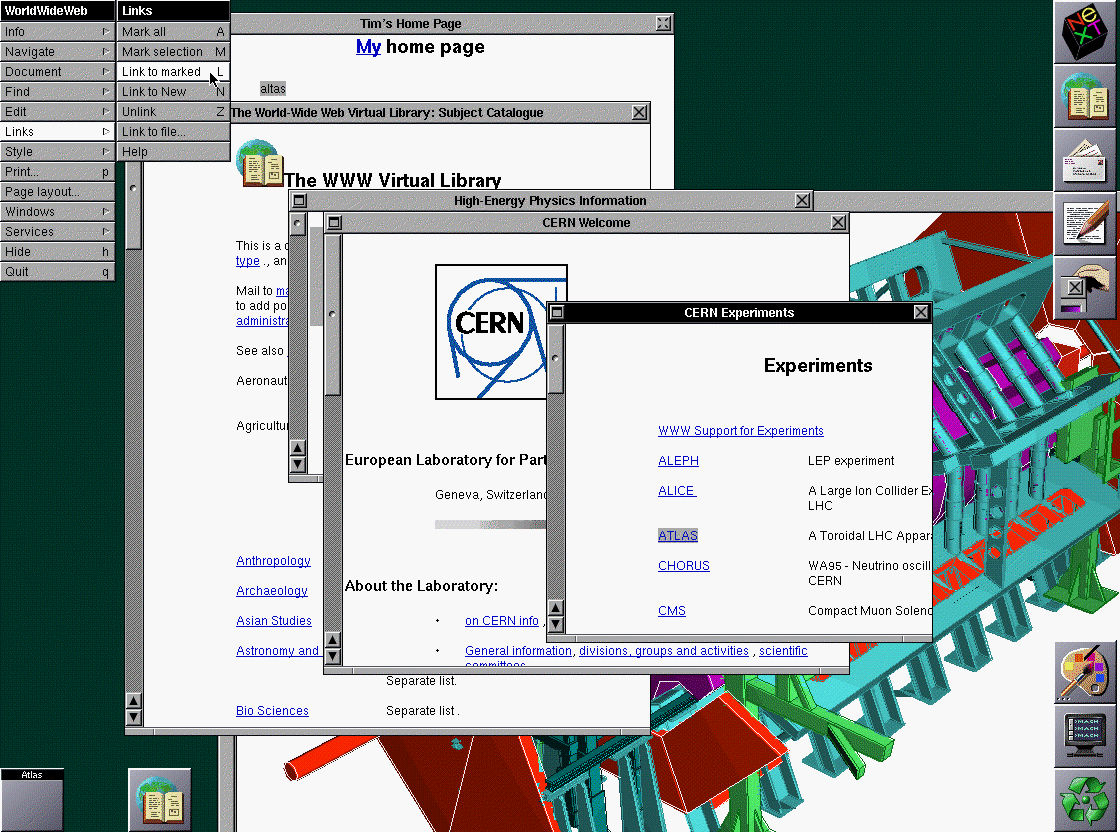
In 1989–1990, the first web browser (named WorldWideWeb, see Figure
4) and web server (named httpd, for HTTP Daemon, according
to UNIX naming conventions) were born, written by Tim Berners-Lee.
Interestingly, while that browser’s capabilities were in some ways
inferior to the browser you will implement in this book,No CSS! No JS! Not even
images! in other ways they go beyond the capabilities
available even in modern browsers.For example, the first browser included the concept of an
index page meant for searching within a site (vestiges of which exist
today in the “index.html” convention when a URL path ends in /”), and
had a WYSIWYG web page editor (the “contenteditable” HTML attribute on
DOM elements (see Chapter 16) has
similar semantic behavior, but built-in file saving is gone). Today, the
index is replaced with a search engine, and web page editors as a
concept are somewhat obsolete due to the highly dynamic nature of
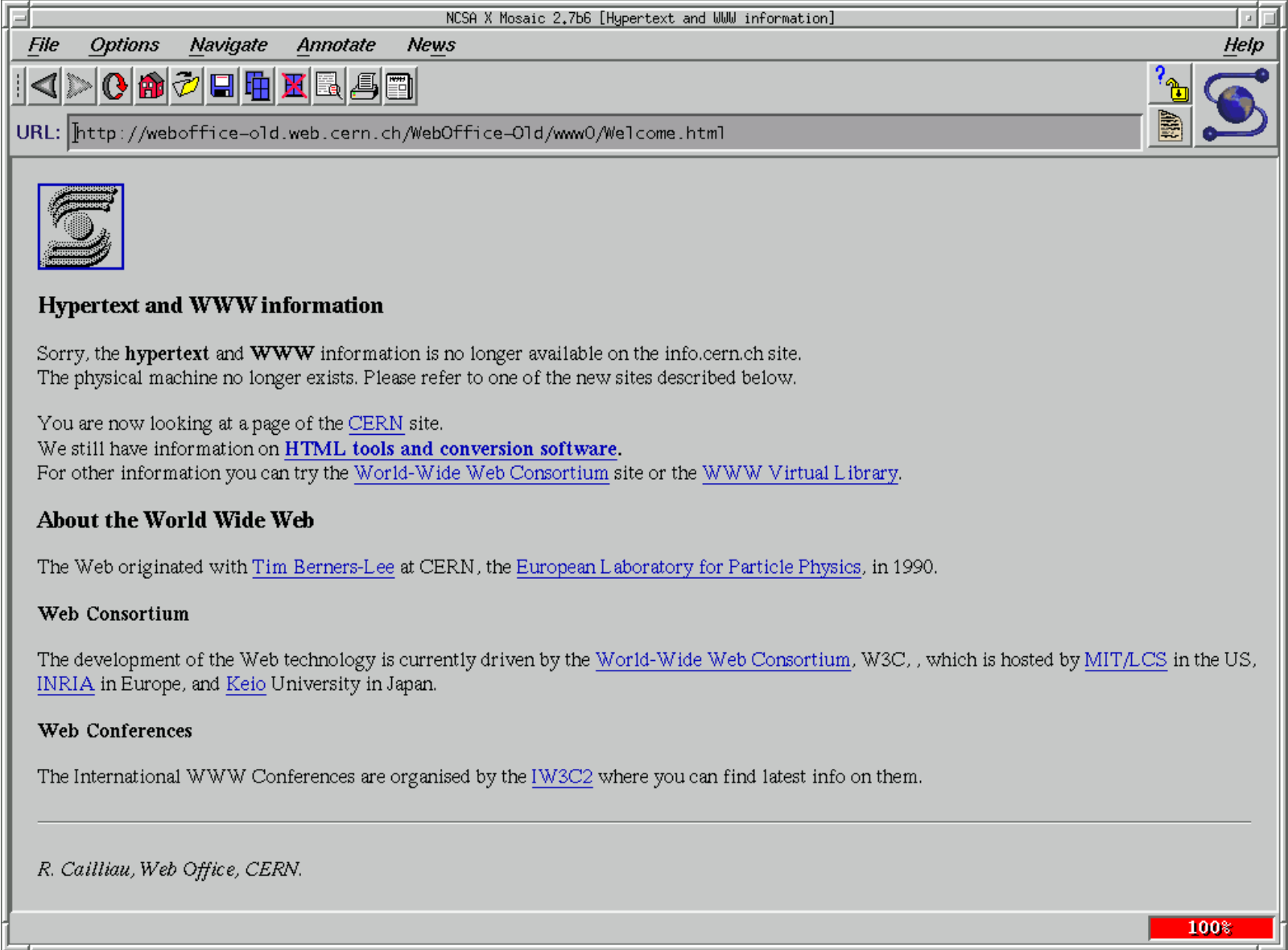
today’s web page rendering. On December 20, 1990 the first web
page was created. The browser we will implement in this book is
easily able to render this web page, even today.Also, as you can see clearly,
that web page has not been updated in the meantime, and retains its
original aesthetics! In 1991, Berners-Lee advertised his
browser and the concept on the alt.hypertext
Usenet group.
Berners-Lee’s Brief History of the Web highlights a number of other key factors that led to the World Wide Web becoming the web we know today. One key factor was its decentralized nature, which he describes as arising from the academic culture of CERN, where he worked. The decentralized nature of the web is a key feature that distinguishes it from many systems that came before or after, and his explanation of it is worth quoting here (the italics are mine):
There was clearly a need for something like EnquireEnquire was a predecessor web-like database system, also written by Berners-Lee. but accessible to everyone. I wanted it to scale so that if two people started to use it independently, and later started to work together, they could start linking together their information without making any other changes. This was the concept of the web.
This quote captures one of the key value propositions of the web: its decentralized nature. The web was successful for several reasons, but they all had to do with decentralization:
Because there was no gatekeeper to doing anything, it was easy for anyone, even novices, to make simple web pages and publish them.
Because pages were identified simply by URLs, traffic could come to the web from outside sources like email, social networking, and search engines. Further, compatibility between sites and the power of hyperlinks created network effects that further strengthened the effect of hyperlinks from within the web.
Because the web was outside the control of any one entity—and kept that way via standards organizations—it avoided the problems of monopoly control and manipulation.
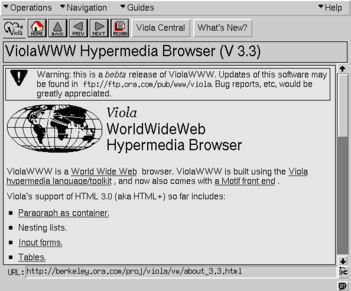
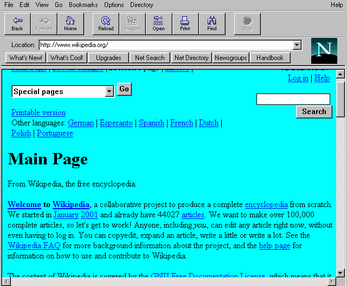
The first widely distributed browser may have been ViolaWWW (see Figure 5); this browser also pioneered multiple interesting features such as applets and images. It was in turn the inspiration for NCSA Mosaic (see Figure 6), which launched in 1993. One of the two original authors of Mosaic went on to co-found Netscape, which built Netscape Navigator (see Figure 7), the first commercial browser,By commercial I mean built by a for-profit entity. Netscape’s early versions were also not free software—you had to buy them from a store. They cost about $50. which launched in 1994. Feeling threatened, Microsoft launched Internet Explorer (see Figure 8) in 1995 and soon bundled it with Windows 95.
The era of the “first browser war” ensued: a competition between Netscape Navigator and Internet Explorer. There were also other browsers with smaller market shares; one notable example is Opera. The KHTML project began in 1999; Safari and Chromium-based browsers, such as Chrome and newer versions of Edge, descend from this codebase. Likewise, the Gecko rendering engine was originally developed by Netscape starting in 1997; the Firefox browser is descended from that codebase. During the first browser war, nearly all of the core features of this book’s simple browser were added, including CSS, DOM, and JavaScript.
The “second browser war”, which according to Wikipedia was 2004–2017,
was fought between a variety of browsers, in particular Internet
Explorer, Firefox, Safari, and Chrome. Initially, Safari and Chrome used
the same rendering engine, but Chrome forked into Blink in
2013, which Microsoft Edge adopted by 2020. The second browser war saw
the development of many features of the modern web, including widespread
use of AJAXAsynchronous
JavaScript and XML, where XML stands for eXtensible Markup
Language., HTML5 features like
<canvas>, and a huge explosion in third-party
JavaScript libraries and frameworks.
In parallel with these developments was another, equally important, one—the standardization of web APIs. In October 1994, the World Wide Web Consortium (W3C) was founded to provide oversight and standards for web features. Prior to this point, browsers would often introduce new HTML elements or APIs, and competing browsers would have to copy them. With a standards organization, those elements and APIs could subsequently be agreed upon and documented in specifications. (These days, an initial discussion, design, and specification precedes any new feature.) Later on, the HTML specification ended up moving to a different standards body called the WHATWG, but CSS and other features are still standardized at the W3C. JavaScript is standardized at yet another standards body, TC39 (Technical Committee 39) at ECMA. HTTP is standardized by the IETF. The important point is that the standards process set up in the mid-1990s is still with us.
In the first years of the web, it was not so clear that browsers would remain standard and that one browser might not end up “winning” and becoming another proprietary software platform. There are multiple reasons this didn’t happen, among them the egalitarian ethos of the computing community and the presence and strength of the W3C. Another important reason was the networked nature of the web, and therefore the necessity for web developers to make sure their pages worked correctly in most or all of the browsers (otherwise they would lose customers), leading them to avoid proprietary extensions. On the contrary, browsers worked hard to carefully reproduce each other’s undocumented behaviors—even bugs—to make sure they continued supporting the whole web.
There never really was a point where any browser openly attempted to break away from the standard, despite fears that that might happen.Perhaps the closest the web came to fragmenting was with the late-1990s introduction of features for DHTML—early versions of the Document Object Model you’ll learn about in this book. Netscape and Internet Explorer at first had incompatible implementations of these features, and it took years, the development of a common specification, and significant pressure campaigns on the browsers before standardization was achieved. You can read about this story in much more depth from Jay Hoffman. Instead, intense competition for market share was channeled into very fast innovation and an ever-expanding set of APIs and capabilities for the web, which we nowadays refer to as the web platform, not just the “World Wide Web”. This recognizes the fact that the web is no longer a document viewing mechanism, but has evolved into a fully realized computing platform and ecosystem.There have even been operating systems built around the web! Examples include webOS, which powered some Palm smartphones, Firefox OS (that today lives on in KaiOS-based phones), and ChromeOS, which is a desktop operating system. All of these operating systems are based on using the web as the UI layer for all applications, with some JavaScript-exposed APIs on top for system integration.
Given the outcomes—multiple competing browsers and well-developed standards—it is in retrospect not that relevant which browser “won” or “lost” each of the browser “wars”. In each case the web won, because it gained users and grew in capability.
Another important and interesting outcome of the second browser war was that all mainstream browsers todayExamples of Chromium-based browsers include Chrome, Edge, Opera (which switched to Chromium from the Presto engine in 2013), Samsung Internet, Yandex Browser, UC Browser, and Brave. In addition, there are many “embedded” browsers, based on one or another of the three engines, for a wide variety of automobiles, phones, TVs, and other electronic devices. are based on three open-source web rendering / JavaScript engines: Chromium, Gecko, and WebKit.The JavaScript engines are actually in different repositories (as are various other subcomponents), and can and do get used outside the browser as JavaScript virtual machines. One important application is the use of V8 to power node.js. However, each of the three rendering engines does have a corresponding JavaScript implementation, so conflating the two is reasonable. Since Chromium and WebKit have a common ancestral codebase, while Gecko is an open-source descendant of Netscape, all three date back to the 1990s—almost to the beginning of the web.
This is not an accident, and in fact tells us something quite interesting about the most cost-effective way to implement a rendering engine based on a commodity set of platform APIs. For example, it’s common for independent developers, not paid by the company nominally controlling the browser, to contribute code and features. There are even companies and individuals that specialize in implementing browser features! It’s also common for features in one browser to copy code from another. And every major browser being open source feeds back into the standards process, reinforcing the web’s decentralized nature.
In summary, the history went like this:
Basic research was performed into ways to represent and explore information.
Once the necessary technology became mature enough, the web proper was proposed and implemented.
The web became popular quite quickly, and many browsers appeared in order to capitalize on the web’s opportunity.
Standards organizations were introduced in order to negotiate between the browsers and avoid proprietary control.
Competition between browsers grew their power and complexity at a rapid pace.
Browsers appeared on all devices and operating systems, from desktop to mobile to embedded.
Eventually, all web rendering engines became open source, as a recognition of their being a shared effort larger than any single entity.
The web has come a long way! But one thing seems clear: it isn’t done yet.
iii-1 What comes next? Based on what you learned about how the web came about and took its current form, what trends do you predict for its future evolution? For example, do you think it’ll compete effectively against other non-web technologies and platforms?
iii-2 What became of the original ideas? The way the web works in practice is significantly different than the memex; one key difference is that there is no built-in way for the user of the web to add links between pages or notate them. Why do you think this is? Can you think of other goals from the original work that remain unrealized?
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}