
A web browser displays information identified by a URL. And the first step is to use that URL to connect to and download information from a server somewhere on the internet.
Browsing the internet starts with a URL,“URL” stands for “uniform resource locator”, meaning that it is a portable (uniform) way to identify web pages (resources) and also that it describes how to access those files (locator). a short string that identifies a particular web page that the browser should visit.
http://example.org/index.html
Figure 1: The syntax of URLs.
A URL has three parts (see Figure 1): the scheme explains how to get the information; the host name explains where to get it; and the path explains what information to get. There are also optional parts to the URL, like ports, queries, and fragments, which we’ll see later.
From a URL, the browser can start the process of downloading the web
page. The browser first asks the local operating system (OS) to put it
in touch with the server described by the host name.
The OS then talks to a Domain Name System (DNS) server which
convertsYou can use a
DNS lookup tool like nslookup.io or
the dig command to do this conversion
yourself. a host name like example.org into a
destination IP address like 93.184.216.34.Today there are two versions
of IP (Internet Protocol): IPv4 and IPv6. IPv6 addresses are a lot
longer and are usually written in hexadecimal, but otherwise the
differences don’t matter here. Then the OS decides which
hardware is best for communicating with that destination IP address
(say, wireless or wired) using what is called a routing table,
and then uses device drivers to send signals over a wire or over the
air.I’m skipping steps
here. On wires you first have to wrap communications in ethernet frames,
on wireless you have to do even more. I’m trying to be
brief. Those signals are picked up and transmitted by a
series of routersOr a switch, or an access point; there are a lot of
possibilities, but eventually there is a router. which
each choose the best direction to send your message so that it
eventually gets to the destination.They may also record where the message came from so they
can forward the reply back. When the message reaches the
server, a connection is created. Anyway, the point of this is that the
browser tells the OS, “Hey, put me in touch with
example.org”, and it does.
On many systems, you can set up this kind of connection using the
telnet program, like this:The “80” is the port,
discussed below.
telnet example.org 80(Note: When you see a gray outline, it means that the code in question is an example only, and not actually part of our browser’s code.)
You might need to install telnet; it is often disabled
by default. On Windows, go to Programs
and Features / Turn Windows features on or off in the Control Panel;
you’ll need to reboot. When you run it, it’ll clear the screen instead
of printing something, but other than that works normally. On macOS, you
can use the nc -v command as a replacement for
telnet:
nc -v example.org 80The output is a little different but it works in the same way. On
most Linux systems, you can install telnet or
nc from the package manager, usually from packages called
telnet and netcat.
You’ll get output that looks like this:
Trying 93.184.216.34...
Connected to example.org.
Escape character is '^]'.This means that the OS converted the host name
example.org into the IP address 93.184.216.34
and was able to connect to it.The line about escape characters is just instructions for
using obscure telnet features. You can now
talk to example.org.
The URL syntax is defined in RFC 3986, whose first author is Tim Berners-Lee—no surprise there! The second author is Roy Fielding, a key contributor to the design of HTTP and also well known for describing the Representational State Transfer (REST) architecture of the web in his Ph.D. thesis, which explains how REST allowed the web to grow in a decentralized way. Today, many services provide “RESTful APIs” that also follow these principles, though there does seem to be some confusion about it.
Once it’s connected, the browser requests information from the server
by giving its path, the path being the part of a URL that comes
after the host name, like /index.html. The structure of the
request is shown in Figure 2. Type this into telnet to try
it.
GET /index.html HTTP/1.0 Host: example.org
Figure 2: An annotated HTTP GET request.
Here, the word GET means that the browser would like to
receive information,It
could say POST if it intended to send information, plus
there are some other, more obscure, options. then comes
the path, and finally there is the word HTTP/1.0 which
tells the host that the browser speaks version 1.0 of HTTP. There
are several versions of HTTP (0.9,
1.0, 1.1, 2.0, and 3.0). The HTTP 1.1 standard adds a variety of
useful features, like keep-alive, but in the interest of simplicity our
browser won’t use them. We’re also not implementing HTTP 2.0; it is much
more complex than the 1.x series, and is intended for large and
complex web applications, which our browser can’t run anyway.
After the first line, each line contains a header, which has
a name (like Host) and a value (like
example.org). Different headers mean different things; the
Host header, for example, tells the server who you think it
is.This is useful when
the same IP address corresponds to multiple host names and hosts
multiple websites (for example, example.com and
example.org). The Host header tells the server
which of multiple websites you want. These websites basically require
the Host header to function properly. Hosting multiple
domains on a single computer is very common. There are
lots of other headers one could send, but let’s stick to just
Host for now.
Finally, after the headers comes a single blank line; that tells the
host that you are done with headers. So type a blank line into
telnet (hit Enter twice after typing the two lines of the
request) and you should get a response from
example.org.
HTTP/1.0 is standardized in RFC 1945, and HTTP/1.1 in
RFC 2616. HTTP was
designed to be simple to understand and implement, making it easy for
any kind of computer to adopt it. It’s no coincidence that you can type
HTTP directly into telnet! Nor is it an accident that HTTP
is a “line-based protocol”, using plain text and newlines, similar to
the Simple Mail Transfer Protocol (SMTP)
for email. Ultimately, the whole pattern derives from early computers
only having line-based text input. In fact, one of the first two
browsers had a line-mode
UI.
The server’s response starts with the line in Figure 3.
HTTP/1.0 200 OK
Figure 3: Annotated first line of an HTTP response.
This tells you that the host confirms that it, too, speaks
HTTP/1.0, and that it found your request to be “OK” (which
has a numeric code of 200). You may be familiar with
404 Not Found; that’s another numeric code and response, as
are 403 Forbidden or 500 Server Error. There
are lots of these codes, and they have a pretty neat organization
scheme:The status text
like OK can actually be anything and is just there for
humans, not for machines.
Note the genius of having two sets of error codes (400s and 500s) to tell you who is at fault, the server or the browser.More precisely, who the server thinks is at fault. You can find a full list of the different codes on Wikipedia, and new ones do get added here and there.
After the 200 OK line, the server sends its own headers.
When I did this, I got these headers (but yours will differ):
Age: 545933
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Mon, 25 Feb 2019 16:49:28 GMT
Etag: "1541025663+gzip+ident"
Expires: Mon, 04 Mar 2019 16:49:28 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (sec/96EC)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1270
Connection: closeThere is a lot here, about the information you are
requesting (Content-Type, Content-Length, and
Last-Modified), about the server (Server,
X-Cache), about how long the browser should cache this
information (Cache-Control, Expires,
Etag), and about all sorts of other stuff. Let’s move on
for now.
After the headers there is a blank line followed by a bunch of HTML code.
This is called the body of the server’s response, and your
browser knows that it is HTML because of the Content-Type
header, which says that it is text/html. It’s this HTML
code that contains the content of the web page itself.
The HTTP request/response transaction is summarized in Figure 4. Let’s now switch gears from making manual connections to Python.
Wikipedia has nice lists of HTTP headers and response codes. Some of the HTTP response codes are almost never used, like 402 “Payment Required”. This code was intended to be used for “digital cash or (micro) payment systems”. While e-commerce is alive and well without the response code 402, micropayments have not (yet?) gained much traction, even though many people (including me!) think they are a good idea.
So far we’ve communicated with another computer using
telnet. But it turns out that telnet is quite
a simple program, and we can do the same programmatically. It’ll require
extracting the host name and path from the URL, creating a
socket, sending a request, and receiving a response.In Python, there’s a library
called urllib.parse for parsing URLs, but I think
implementing our own will be good for learning. Plus, it makes this book
less Python-specific.
Let’s start with parsing the URL. I’m going to make parsing a URL
return a URL object, and I’ll put the parsing code into the
constructor:
class URL:
def __init__(self, url):
# ...The __init__ method is Python’s peculiar syntax for
class constructors, and the self parameter, which you must
always make the first parameter of any method, is Python’s analog of
this in C++ or Java.
Let’s start with the scheme, which is separated from the rest of the
URL by ://. Our browser only supports http, so
let’s check that, too:
class URL:
def __init__(self, url):
self.scheme, url = url.split("://", 1)
assert self.scheme == "http"Now we must separate the host from the path. The host comes before
the first /, while the path is that slash and everything
after it:
class URL:
def __init__(self, url):
# ...
if "/" not in url:
url = url + "/"
self.host, url = url.split("/", 1)
self.path = "/" + url(When you see a code block with a # ..., like this one,
that means you’re adding code to an existing method or block.) The
split(s, n) method splits a string at the first
n copies of s. Note that there’s some tricky
logic here for handling the slash between the host name and the path.
That (optional) slash is part of the path.
Now that the URL has the host and
path fields, we can download the web page at that URL.
We’ll do that in a new method, request:
class URL:
def request(self):
# ...Note that you always need to write the self parameter
for methods in Python. In the future, I won’t always make such a big
deal out of defining a method—if you see a code block with code in a
method or function that doesn’t exist yet, that means we’re defining
it.
The first step to downloading a web page is connecting to the host. The operating system provides a feature called “sockets” for this. When you want to talk to other computers (either to tell them something, or to wait for them to tell you something), you create a socket, and then that socket can be used to send information back and forth. Sockets come in a few different kinds, because there are multiple ways to talk to other computers:
AF. We want AF_INET, but for example
AF_BLUETOOTH is another.SOCK. We want SOCK_STREAM, which means each
computer can send arbitrary amounts of data, but there’s also
SOCK_DGRAM, in which case they send each other packets of
some fixed size.DGRAM stands for “datagram”, which I imagine
to be like a postcard.IPPROTO_TCP.Newer versions of HTTP use
something called QUIC
instead of the Transmission Control Protocol (TCP), but our browser will
stick to HTTP 1.0.By picking all of these options, we can create a socket like so:While this code uses the
Python socket library, your favorite language likely
contains a very similar library; the API is basically standardized. In
Python, the flags we pass are defaults, so you can actually call
socket.socket(); I’m keeping the flags here in case you’re
following along in another language.
import socket
class URL:
def request(self):
s = socket.socket(
family=socket.AF_INET,
type=socket.SOCK_STREAM,
proto=socket.IPPROTO_TCP,
)Once you have a socket, you need to tell it to connect to the other computer. For that, you need the host and a port. The port depends on the protocol you are using; for now it should be 80.
class URL:
def request(self):
# ...
s.connect((self.host, 80))This talks to example.org to set up the connection and
prepare both computers to exchange data.
Naturally this won’t work if you’re offline. It also might not work if you’re behind a proxy, or in a variety of more complex networking environments. The workaround will depend on your setup—it might be as simple as disabling your proxy, or it could be much more complex.
Note that there are two parentheses in the connect call:
connect takes a single argument, and that argument is a
pair of a host and a port. This is because different address families
have different numbers of arguments.
The “sockets” API, which Python more or less implements directly, derives from the original “Berkeley sockets” API design for 4.2 BSD Unix in 1983. Of course, Windows and Linux merely reimplement the API, but macOS and iOS actually do still use large amounts of code descended from BSD Unix.
Now that we have a connection, we make a request to the other server.
To do so, we send it some data using the send method:
class URL:
def request(self):
# ...
request = "GET {} HTTP/1.0\r\n".format(self.path)
request += "Host: {}\r\n".format(self.host)
request += "\r\n"
s.send(request.encode("utf8"))The send method just sends the request to the
server.send
actually returns a number, in this case 47. That tells you
how many bytes of data you sent to the other computer; if, say, your
network connection failed midway through sending the data, you might
want to know how much you sent before the connection
failed. There are a few things in this code that have to
be exactly right. First, it’s very important to use \r\n
instead of \n for newlines. It’s also essential that you
put two \r\n newlines at the end, so that you send
that blank line at the end of the request. If you forget that, the other
computer will keep waiting on you to send that newline, and you’ll keep
waiting on its response.Computers are endlessly literal-minded.
Also note the encode call. When you send data, it’s
important to remember that you are sending raw bits and bytes; they
could form text or an image or video. But a Python string is
specifically for representing text. The encode method
converts text into bytes, and there’s a corresponding
decode method that goes the other way.When you call
encode and decode you need to tell the
computer what character encoding you want it to use. This is a
complicated topic. I’m using utf8 here, which is a common
character encoding and will work on many pages, but in the real world
you would need to be more careful. Python reminds you to
be careful by giving different types to text and to bytes:
>>> type("text")
<class 'str'>
>>> type("text".encode("utf8"))
<class 'bytes'>If you see an error about str versus bytes,
it’s because you forgot to call encode or
decode somewhere.
To read the server’s response, you could use the read
function on sockets, which gives whatever bits of the response have
already arrived. Then you write a loop to collect those bits as they
arrive. However, in Python you can use the makefile helper
function, which hides the loop:If you’re in another language, you might only have
socket.read available. You’ll need to write the loop,
checking the socket status, yourself.
class URL:
def request(self):
# ...
response = s.makefile("r", encoding="utf8", newline="\r\n")Here, makefile returns a file-like object containing
every byte we receive from the server. I am instructing Python to turn
those bytes into a string using the utf8 encoding,
or method of associating bytes to letters.Hard-coding utf8
is not correct, but it’s a shortcut that will work alright on most
English-language websites. In fact, the Content-Type header
usually contains a charset declaration that specifies the
encoding of the body. If it’s absent, browsers still won’t default to
utf8; they’ll guess, based on letter frequencies, and you
will see ugly � strange áççêñ£ß when they guess wrong. I’m
also informing Python of HTTP’s weird line endings.
Let’s now split the response into pieces. The first line is the status line:I could have asserted that 200 is required, since that’s the only code our browser supports, but it’s better to just let the browser render the returned body, because servers will generally output a helpful and user-readable HTML error page even for error codes. This is another way in which the web is easy to implement incrementally.
class URL:
def request(self):
# ...
statusline = response.readline()
version, status, explanation = statusline.split(" ", 2)Note that I do not check that the server’s version of HTTP is the same as mine; this might sound like a good idea, but there are a lot of misconfigured servers out there that respond in HTTP 1.1 even when you talk to them in HTTP 1.0.Luckily the protocols are similar enough to not cause confusion.
After the status line come the headers:
class URL:
def request(self):
# ...
response_headers = {}
while True:
line = response.readline()
if line == "\r\n": break
header, value = line.split(":", 1)
response_headers[header.casefold()] = value.strip()For the headers, I split each line at the first colon and fill in a
map of header names to header values. Headers are case-insensitive, so I
normalize them to lower case.I used casefold
instead of lower, because it works better for more
languages. Also, whitespace is insignificant in HTTP
header values, so I strip off extra whitespace at the beginning and
end.
Headers can describe all sorts of information, but a couple of headers are especially important because they tell us that the data we’re trying to access is being sent in an unusual way. Let’s make sure none of those are present.Exercise 1-9 describes how your browser should handle these headers if they are present.
class URL:
def request(self):
# ...
assert "transfer-encoding" not in response_headers
assert "content-encoding" not in response_headersThe usual way to get the sent data, then, is everything after the headers:
class URL:
def request(self):
# ...
content = response.read()
s.close()It’s the body that we’re going to display, so let’s return that:
class URL:
def request(self):
# ...
return contentNow let’s actually display the text in the response body.
The Content-Encoding
header lets the server compress web pages before sending them. Large,
text-heavy web pages compress well, and as a result the page loads
faster. The browser needs to send an Accept-Encoding
header in its request to list the compression algorithms it
supports. Transfer-Encoding
is similar and also allows the data to be “chunked”, which many servers
seem to use together with compression.
The HTML code in the response body defines the content you see in
your browser window when you go to
http://example.org/index.html. I’ll be talking much, much
more about HTML in future chapters, but for now let me keep it very
simple.
In HTML, there are tags and text. Each tag starts
with a < and ends with a >; generally
speaking, tags tell you what kind of thing some content is, while text
is the actual content.That said, some tags, like img, are content,
not information about it. Most tags come in pairs of a
start and an end tag; for example, the title of the page is enclosed in
a pair of tags: <title> and
</title>. Each tag, inside the angle brackets, has a
tag name (like title here), and then optionally a space
followed by attributes, and its pair has a /
followed by the tag name (and no attributes).
So, to create our very, very simple web browser, let’s take the page
HTML and print all the text, but not the tags, in it.If this example causes Python
to produce a SyntaxError pointing to the end
on the last line, it is likely because you are running Python 2 instead
of Python 3. Make sure you are using Python 3. I’ll do
this in a new function, show:Note that this is a global
function and not in the URL class.
def show(body):
in_tag = False
for c in body:
if c == "<":
in_tag = True
elif c == ">":
in_tag = False
elif not in_tag:
print(c, end="")This code is pretty complex. It goes through the request body
character by character, and it has two states: in_tag, when
it is currently between a pair of angle brackets, and
not in_tag. When the current character is an angle bracket,
it changes between those states; normal characters, not inside a tag,
are printed.The
end argument tells Python not to print a newline after the
character, which it otherwise would.
We can now load a web page just by stringing together
request and show:Like show, this
is a global function.
def load(url):
body = url.request()
show(body)Add the following code to run load from the command
line:
if __name__ == "__main__":
import sys
load(URL(sys.argv[1]))The first line is Python’s version of a main function,
run only when executing this script from the command line. The code
reads the first argument (sys.argv[1]) from the command
line and uses it as a URL. Try running this code on the URL
http://example.org/:
python3 browser.py http://example.org/You should see some short text welcoming you to the official example web page. You can also try using it on this chapter!
HTML, just like URLs and HTTP, is designed to be very easy to parse and display at a basic level. And in the beginning there were very few features in HTML, so it was possible to code up something not so much more fancy than what you see here, yet still display the content in a usable way. Even our super simple and basic HTML parser can already print out the text of the browser.engineering website.
So far, our browser supports the http scheme. That’s a
pretty common scheme. But more and more websites are migrating to the
https scheme, and many websites require it.
The difference between http and https is
that https is more secure—but let’s be a little more
specific. The https scheme, or more formally HTTP over TLS
(Transport Layer Security), is identical to the normal http
scheme, except that all communication between the browser and the host
is encrypted. There are quite a few details to how this works: which
encryption algorithms are used, how a common encryption key is agreed
to, and of course how to make sure that the browser is connecting to the
correct host. The difference in the protocol layers involved is shown in
Figure 5.
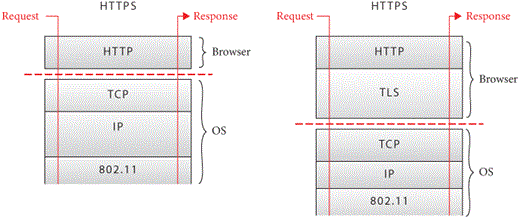
Luckily, the Python ssl library implements all of these
details for us, so making an encrypted connection is almost as easy as
making a regular connection. That ease of use comes with accepting some
default settings which could be inappropriate for some situations, but
for teaching purposes they are fine.
Making an encrypted connection with ssl is pretty easy.
Suppose you’ve already created a socket, s, and connected
it to example.org. To encrypt the connection, you use
ssl.create_default_context to create a context
ctx and use that context to wrap the socket
s:
import ssl
ctx = ssl.create_default_context()
s = ctx.wrap_socket(s, server_hostname=host)Note that wrap_socket returns a new socket, which I save
back into the s variable. That’s because you don’t want to
send any data over the original socket; it would be unencrypted and also
confusing. The server_hostname argument is used to check
that you’ve connected to the right server. It should match the
Host header.
On macOS, you’ll need to run
a program called “Install Certificates” before you can use Python’s
ssl package on most websites.
Let’s try to take this code and add it to request.
First, we need to detect which scheme is being used:
import ssl
class URL:
def __init__(self, url):
self.scheme, url = url.split("://", 1)
assert self.scheme in ["http", "https"]
# ...(Note that here you’re supposed to replace the existing scheme parsing code with this new code. It’s usually clear from context, and the code itself, what you need to replace.)
Encrypted HTTP connections usually use port 443 instead of port 80:
class URL:
def __init__(self, url):
# ...
if self.scheme == "http":
self.port = 80
elif self.scheme == "https":
self.port = 443We can use that port when creating the socket:
class URL:
def request(self):
# ...
s.connect((self.host, self.port))
# ...Next, we’ll wrap the socket with the ssl library:
class URL:
def request(self):
# ...
s.connect((self.host, self.port))
if self.scheme == "https":
ctx = ssl.create_default_context()
s = ctx.wrap_socket(s, server_hostname=self.host)
# ...Your browser should now be able to connect to HTTPS sites.
While we’re at it, let’s add support for custom ports, which are specified in a URL by putting a colon after the host name, as in Figure 6.
http://example.org:8080/index.html
Figure 6: Where the port goes in a URL.
If the URL has a port we can parse it out and use it:
class URL:
def __init__(self, url):
# ...
if ":" in self.host:
self.host, port = self.host.split(":", 1)
self.port = int(port)Custom ports are handy for debugging. Python has a built-in web server you can use to serve files on your computer. For example, if you run
python3 -m http.server 8000 -d /some/directorythen going to http://localhost:8000/ should show you all
the files in that directory. This is a good way to test your
browser.
TLS is pretty complicated. You can read the details in RFC 8446, but implementing your own is not recommended. It’s very difficult to write a custom TLS implementation that is not only correct but secure.
At this point you should be able to run your program on any web page. Here is what it should output for a simple example:
This is a simple
web page with some
text in it.
This chapter went from an empty file to a rudimentary web browser that can:
socket and
ssl libraries;Host
header;Yes, this is still more of a command-line tool than a web browser, but it already has some of the core capabilities of a browser.
The complete set of functions, classes, and methods in our browser should look something like this:
class URL:
def __init__(url)
def request()
def show(body)
def load(url)
1-1 HTTP/1.1. Along with Host, send the
Connection header in the request function with
the value close. Your browser can now declare that it is
using HTTP/1.1. Also add a User-Agent header.
Its value can be whatever you want—it identifies your browser to the
host. Make it easy to add further headers in the future.
1-2 File URLs. Add support for the file scheme,
which allows the browser to open local files. For example,
file:///path/goes/here should refer to the file on your
computer at location /path/goes/here. Also make it so that,
if your browser is started without a URL being given, some specific file
on your computer is opened. You can use that file for quick testing.
1-3 data. Yet another scheme is
data, which allows inlining HTML content into the URL
itself. Try navigating to data:text/html,Hello world! in a
real browser to see what happens. Add support for this scheme to your
browser. The data scheme is especially convenient for
making tests without having to put them in separate files.
1-4 Entities. Implement support for the less-than
(<) and greater-than (>)
entities. These should be printed as < and
>, respectively. For example, if the HTML response was
<div>, the show method of your
browser should print <div>. Entities allow web pages
to include these special characters without the browser interpreting
them as tags.
1-5 view-source. Add support for the
view-source scheme; navigating to
view-source:http://example.org/ should show the HTML source
instead of the rendered page. Add support for this scheme. Your browser
should print the entire HTML file as if it was text. You’ll want to have
also implemented Exercise 1-4.
1-6 Keep-alive. Implement Exercise 1-1; however, do not send
the Connection: close header (send
Connection: keep-alive instead). When reading the body from
the socket, only read as many bytes as given in the
Content-Length header and don’t close the socket afterward.
Instead, save the socket, and if another request is made to the same
server reuse the same socket instead of creating a new one. (You’ll also
need to pass the "rb" option to makefile or
the value reported by Content-Length might not match the
length of the string you’re reading.) This will speed up repeated
requests to the same server, which are common.
1-7 Redirects. Error codes in the 300 range request a
redirect. When your browser encounters one, it should make a new request
to the URL given in the Location header. Sometimes the
Location header is a full URL, but sometimes it skips the
host and scheme and just starts with a / (meaning the same
host and scheme as the original request). The new URL might itself be a
redirect, so make sure to handle that case. You don’t, however, want to
get stuck in a redirect loop, so make sure to limit how many redirects
your browser can follow in a row. You can test this with the URL http://browser.engineering/redirect, which redirects
back to this page, and its /redirect2 and /redirect3 cousins which
do more complicated redirect chains.
1-8 Caching. Typically, the same images, styles, and scripts
are used on multiple pages; downloading them repeatedly is a waste. It’s
generally valid to cache any HTTP response, as long as it was requested
with GET and received a 200 response.Some other status codes like
301 and 404 can also be cached.
Implement a cache in your browser and test it by requesting the same
file multiple times. Servers control caches using the
Cache-Control header. Add support for this header,
specifically for the no-store and max-age
values. If the Cache-Control header contains any value
other than these two, it’s best not to cache the response.
1-9 Compression. Add support for HTTP compression, in which
the browser informs
the server that compressed data is acceptable. Your browser must
send the Accept-Encoding header with the value
gzip. If the server supports compression, its response will
have a Content-Encoding header with value
gzip. The body is then compressed. Add support for this
case. To decompress the data, you can use the decompress
method in the gzip module. GZip data is not
utf8-encoded, so pass "rb" to
makefile to work with raw bytes instead. Most web servers
send compressed data in a Transfer-Encoding called chunked.There are also a couple of
Transfer-Encodings that compress the data. They aren’t
commonly used. You’ll need to add support for that,
too.
Did you find this chapter useful?