
Compositing (see Chapter 13) makes animations smoother, but it doesn’t help with interactions that affect layout, like text editing or DOM modifications. Luckily, we can avoid redundant layout work by treating the layout tree as a kind of cache, and only recomputing the parts that change. This invalidation technique is traditionally complex and bug-prone, but we’ll use a principled approach and simple abstractions to make it manageable.
In Chapter 13, we used compositing to smoothly animate CSS properties
like transform or opacity. But we couldn’t
animate layout-inducing properties like width or
font-size this way because they change not only the
display list but also the layout tree. And while it’s
best to avoid animating layout-inducing properties, many user
interactions that change the layout tree need to be responsive.
One good example is editing text. People type pretty quickly, so even
a few frames’ delay is distracting. But editing changes the HTML tree
and therefore the layout tree. Rebuilding the layout tree from scratch,
which our browser currently does, can be very slow on complex pages.
Try, for example, loading the web version of
this chapter in our browser and typing into the input box that
appears after this paragraph … You’ll find that it is much too
slow—1.7 seconds just in render (see Figure 1)!Trace here.
Typing into input elements could be special-cased,The input element
doesn’t change size as you type, and the text in the input
element doesn’t get its own layout object, so typing into an
input element doesn’t really have to induce layout, just
paint. but there are other text editing APIs that can’t
be. For example, the contenteditable attribute makes any
element editable.The
contenteditable attribute can turn any element on any page
into a living document. It’s how we implemented the “typo” feature for
this book: type Ctrl-E (or Cmd-E on a Mac) to
turn it on. The source code is on the website; see
the typo_mode function for the contenteditable
attribute.
Click on this formatted text to edit it, including rich text!
Let’s implement the most basic possible version of
contenteditable in our browser—it’s a useful feature and
also a good test of invalidation. To begin with, we need to make
elements with a contenteditable property focusable:Actually, in real browsers,
contenteditable can be set to true or
false, and false is useful in case you want to
have a non-editable element inside an editable one. But I’m not going to
implement that in our browser.
def is_focusable(node):
# ...
elif "contenteditable" in node.attributes:
return True
# ...Once we’re focused on an editable node, typing should edit it. A real browser would handle cursor movement and all kinds of complications, but I’ll keep it simple and just add each character to the last text node in the editable element. First we need to find that text node:
class Frame:
def keypress(self, char):
# ...
elif self.tab.focus and \
"contenteditable" in self.tab.focus.attributes:
text_nodes = [
t for t in tree_to_list(self.tab.focus, [])
if isinstance(t, Text)
]
if text_nodes:
last_text = text_nodes[-1]
else:
last_text = Text("", self.tab.focus)
self.tab.focus.children.append(last_text)Note that if the editable element has no text children, we create a new one. Then we add the typed character to this element:
class Frame:
def keypress(self, char):
elif self.tab.focus and \
"contenteditable" in self.tab.focus.attributes:
# ...
last_text.text += char
self.set_needs_render()This is enough to make editing work, but it’s convenient to also draw
a cursor to confirm that the element is focused and show where edits
will go. Let’s do that in BlockLayout:
class BlockLayout:
def paint(self):
# ...
if self.node.is_focused \
and "contenteditable" in self.node.attributes:
text_nodes = [
t for t in tree_to_list(self, [])
if isinstance(t, TextLayout)
]
if text_nodes:
cmds.append(DrawCursor(text_nodes[-1],
text_nodes[-1].width))
else:
cmds.append(DrawCursor(self, 0))
# ...Here, DrawCursor is just a wrapper around
DrawLine:
def DrawCursor(elt, offset):
x = elt.x + offset
return DrawLine(x, elt.y, x, elt.y + elt.height, "red", 1)We might as well also use this wrapper in
InputLayout:
class InputLayout(EmbedLayout):
def paint(self):
if self.node.is_focused and self.node.tag == "input":
cmds.append(DrawCursor(self, self.font.measureText(text)))You can now edit the examples on this chapter’s page in your browser—but each key stroke will take more than a second, making for a frustrating editing experience. So let’s work on speeding that up.
Text editing is exceptionally
hard if you include tricky concepts like caret affinity (which line
the cursor is on, if a long line is wrapped in the middle of a word),
Unicode handling, bidirectional text, and
mixing text formatting with editing. So it’s a good thing browsers
implement all this complexity and hide it behind
contenteditable.
Fundamentally, the reason editing this page is slow in our browser is
that it’s pretty big. After all, it’s not handling the keypress that’s
slow: appending a character to a Text node takes almost no
time. What takes time is re-rendering the whole page afterward.
We want interactions to be fast, even on large, complex pages, so we want re-rendering the page to take time proportional to the size of the change, and not proportional to the size of the page. I call this the principle of incremental performance, and it’s crucial for handling large and complex web applications. Not only does it make text editing fast, it also means that developers can think about performance one change at a time, without considering the contents of the whole page. Incremental performance is therefore necessary for complex applications.
But the principle of incremental performance also really constrains our browser implementation. For example, even traversing the whole layout tree would take time proportional to the whole page, not the change being made, so we can’t even afford to do that.
To achieve incremental performance, we’re going to need to think of
the initial render and later re-renders differently.While initial and later
renders are in some ways conceptually different, they’ll use the same
code path. Basically, the initial render will be one big change from no
page to the initial page, while later re-renders will handle smaller
changes. After all, a page could use innerHTML to replace
the whole page; that would be a big change, and rendering it would take
time proportional to the whole page, because the change is the size of
the whole page! The point is: all of these will ultimately use the same
code path. When the page is first loaded, rendering will
take time proportional to the size of the page. But we’ll treat that
initial render as a cache. Later renders will invalidate and
recompute parts of that cache, taking time proportional to the size of
the change, but won’t touch most of the page.I’m sure there are all sorts
of performance improvements possible without implementing the
invalidation techniques from this chapter, but invalidation is still
essential for incremental performance, which is a kind of asymptotic
guarantee that micro-optimization alone won’t achieve. In
a real browser, every step of the rendering pipeline needs to be
incremental, but this chapter focuses on layout.Why layout? Because layout is
both important and complex enough to demonstrate most of the core
challenges and techniques.
The key to this cache-and-invalidate approach will be tracking the
effects of changes. When one part of the page, like a style
attribute, changes, other things that depend on it, like that element’s
size, change as well. So we’ll need to construct a detailed
dependency graph, down to the level of each layout field, and
use that graph to determine what to recompute. It will be similar to our
needs_style and needs_layout flags, scaled way
up. Most of this chapter is thus about tracking dependencies in the
dependency graph, and building abstractions to help us do that. To use
those abstractions, we’ll need to refactor our layout engine
significantly. But incrementalizing layout will allow us to skip the two
most expensive parts of layout: building the layout tree and traversing
it to compute layout fields. When we’re done, re-layout will take under
a millisecond for small changes like text editing.
The principle of incremental performance is part of what makes browsers a good platform. Remember that the web is declarative: web pages only concern themselves with describing how the page looks, and it’s up to the browser to implement that description. To us browser engineers, that creates a whole bunch of complexity. But think about the web as a whole—it involves not just browser engineers, but web developers and users as well. Implementing complex invalidation algorithms in the browser lets web developers focus on making more interesting applications and gives users a better, more responsive experience. The declarative web makes it possible for the invalidation algorithms to be written once and then automatically benefit everyone.
If we want to implement this caching-and-invalidation idea, the first roadblock is that our browser rebuilds the layout tree from scratch every time the layout phase runs:
class Frame:
def render(self):
if self.needs_layout:
self.document = DocumentLayout(self.nodes, self)
self.document.layout(self.frame_width, self.tab.zoom)
# ...By starting over with a new DocumentLayout, we ignore
all of the old layout information and start from scratch; we are
essentially invalidating the whole tree. So our first
optimization has to be avoiding that, reusing as many layout objects as
possible. That both saves time allocating memory and makes the
caching-and-invalidation approach possible by keeping around the old
layout information.
But before jumping right to coding, let’s review how layout objects
are created. Search your browser code for Layout, which all
layout class names end with. You should see that layout objects are
created in just a few places:
DocumentLayout objects are created by the
Frame in render;BlockLayout objects are created by either:
DocumentLayout, in layout, orBlockLayout, in layout;LineLayout objects are created by
BlockLayout in new_line;BlockLayout in
add_inline_child.Let’s start with DocumentLayout. It’s created in
render, and its two parameters, nodes and
self, are the same every time. This means that identical
DocumentLayouts are created each time.This wouldn’t be true if the
DocumentLayout constructor had side-effects or read global
state, but it doesn’t do that. That’s wasteful; let’s
create the DocumentLayout just once, in
load:
class Frame:
def load(self, url, payload=None):
# ...
self.document = DocumentLayout(self.nodes, self)
self.set_needs_render()
def render(self):
if self.needs_layout:
self.document.layout(self.frame_width, self.tab.zoom)
# ...Moving on, let’s look at where DocumentLayout constructs
a BlockLayout:
class DocumentLayout:
def layout(self, width, zoom):
child = BlockLayout(self.node, self, None, self.frame)
# ...Once again, the constructor parameters cannot change, so again we can skip reconstructing this layout object, like so:
class DocumentLayout:
def layout(self, width, zoom):
if not self.children:
child = BlockLayout(self.node, self, None, self.frame)
else:
child = self.children[0]
# ...But don’t run your browser with these changes just yet! By reusing
layout objects, we end up running layout multiple times on
the same object. That’s not how layout is intended to work,
and it causes all sorts of weird behavior. For example, after the
DocumentLayout creates its child BlockLayout,
it appends it to the children array:
class DocumentLayout:
def layout(self, width, zoom):
# ...
self.children.append(child)
# ...But we don’t want to append the same child more than
once!
The issue here is called idempotence: repeated calls to
layout shouldn’t repeatedly change state. More formally, a
function is idempotent if calling it twice in a row with the same inputs
and dependencies yields the same result. Assigning a field is
idempotent: assigning the same value for a second time is a no-op. But
methods like append aren’t idempotent.
We’ll need to fix any non-idempotent method calls. In
DocumentLayout, we can switch from append to
assignment:
class DocumentLayout:
def layout(self, width, zoom):
# ...
self.children = [child]
# ...BlockLayout also calls append on its
children array. We can fix that by resetting the
children array in layout. I’ll put separate
reset code in the block and inline cases:
class BlockLayout:
def layout(self):
if mode == "block":
self.children = []
# ...
else:
self.children = []
# ...This makes the BlockLayout’s layout
function idempotent because each call will start over from a new
children array.
Before we try running our browser, let’s read through all of the
other layout methods, noting any subroutine calls that
might not be idempotent. I found:If you’ve being doing exercises throughout this book, there
might be more, in which case there might be more calls. In any case, the
core idea is replacing non-idempotent calls with idempotent
ones.
new_line, BlockLayout will append to
its children array.add_inline_child, BlockLayout will
append to the children array of some
LineLayout child.add_inline_child, BlockLayout will call
get_font, as will the TextLayout and
InputLayout methods.dpx.The new_line and add_inline_child methods
are only called through layout, which resets the
children array, so they don’t break idempotency. The
get_font function acts as a cache, so multiple calls return
the same font object, maintaining idempotency. And dpx just
does math, so it always returns the same result given the same inputs.
In other words all of our layout methods are now
idempotent.
It’s therefore safe to call layout multiple times on the
same object—which is exactly what we’re now doing. More generally, since
it doesn’t matter how many times an idempotent function is
called, we can skip redundant calls! That makes idempotency the
foundation for the rest of this chapter, which is all about skipping
redundant work.
HTTP also features a notion
of idempotency, but that notion is subtly different from the one
we’re discussing here because HTTP involves both a client and a server.
In HTTP, idempotence only covers the effects of a request on the server
state, not the response. So, for example, requesting the same page twice
with GET might result in different responses (if the page
has changed) but the request is still idempotent because it didn’t make
any change to the server. And HTTP idempotence also only covers
client-visible state, so for example it’s possible that the first
GET request goes to cache while the second doesn’t, or it’s
possible that each one adds a separate log entry.
So far, we’re only reusing two layout objects: the
DocumentLayout, and the root BlockLayout.
Let’s look at the other BlockLayouts, created here:
class BlockLayout:
def layout(self):
self.children = []
# ...
if mode == "block":
previous = None
for child in self.node.children:
next = BlockLayout(child, self, previous, self.frame)
self.children.append(next)
previous = next
# ...This code is a little more complicated than the code that creates the
root BlockLayout: the child and
previous arguments come from node.children,
and that children array can change—as a result of
contenteditable edits or innerHTML calls.Or any other exercises and
extensions that you’ve implemented. Moreover, in order to
even run this code, the node’s layout_mode has to be
block, and layout_mode itself also reads the
node’s children.It also looks at the node’s tag and the node’s
children’s tags, but tags can’t change, so we
don’t need to think about them as dependencies. In invalidation we care
only about dependencies that can change. This makes it
harder to know when we need to recreate the
BlockLayouts.
Recall that idempotency means that calling a function again with
the same inputs and dependencies yields the same result. Here, the
inputs can change, so we can only avoid redundant re-execution if
the node’s children field hasn’t changed. So we need a
way of knowing whether that children field has changed.
We’re going to use a dirty flag:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.children_dirty = TrueWe’ve seen dirty flags before—like needs_layout and
needs_draw—but layout is more complex and we’re going to
need to think about dirty flags a bit more rigorously.
Every dirty flag protects a certain field; this one protects
a BlockLayout’s children field. A dirty flag
has a certain life cycle: it can be set, checked, and reset. The dirty
flag starts out True, and is set to True when
an input or dependency of the field changes, marking the protected
field as unusable. Then, before using the protected field, the
dirty flag must be checked. The flag is reset to False only
when the protected field is recomputed.
So let’s analyze the children_dirty flag in this way.
Dirty flags have to be set if any dependencies of the fields
they protect change. In this case, the dirty flag protects the
children field of a BlockLayout, which in turn
depends on the children field of the associated
Element. That means that any time an Element’s
children field is modified, we need to set the dirty flag
for the associated BlockLayout:
class JSContext:
def innerHTML_set(self, handle, s, window_id):
# ...
obj = elt.layout_object
while not isinstance(obj, BlockLayout):
obj = obj.parent
obj.children_dirty = TrueLikewise, we need to set the dirty flag any time we edit a
contenteditable element, since that can also affect the
children of a node:
class Frame:
def keypress(self, char):
elif self.tab.focus and \
"contenteditable" in self.tab.focus.attributes:
# ...
obj = self.tab.focus.layout_object
while not isinstance(obj, BlockLayout):
obj = obj.parent
obj.children_dirty = TrueIt’s important that all dependencies of the protected field set the dirty bit. This can be challenging, since it requires being vigilant about which fields depend on which others. But if we do forget to set the dirty bit, we’ll sometimes fail to recompute the protected fields, which means we’ll display the page incorrectly. Typically these bugs look like unpredictable layout glitches, and they can be very hard to debug—so we need to be careful.
Anyway, now that we’re setting the dirty flag, the next step is
checking it before using the protected field. BlockLayout
uses its children field in three places: to recursively
call layout on all its children, to compute its
height, and to paint itself. Let’s add a check
in each place:
class BlockLayout:
def layout(self):
# ...
assert not self.children_dirty
for child in self.children:
child.layout()
assert not self.children_dirty
self.height = sum([child.height for child in self.children])
def paint(self, display_list):
assert not self.children_dirty
# ...It’s tempting to skip these assertions, since they should never be triggered, but coding defensively like this catches bugs earlier and makes them easier to debug. It’s very easy to invalidate fields in the wrong order, or skip a computation when it’s actually important, and you’d rather that trigger a crash rather than a subtly incorrect rendering—at least when debugging a toy browser!Real browsers prefer not to crash, however—better a slightly wrong page than a browser that is crashing all the time. So in release mode browsers turn off these assertions, or at least make them not crash the browser.
Finally, when the field is recomputed we need to reset the dirty
flag. Here, we reset the flag when we’ve recomputed the
children array:
class BlockLayout:
def layout(self):
if mode == "block":
# ...
self.children_dirty = False
else:
# ...
self.children_dirty = FalseNow that we have all three parts of the dirty flag done, you should
be able to run your browser and test it on this chapter’s
page. Even when you edit text or call innerHTML, you
shouldn’t see any assertion failures. Work incrementally and test
often—it makes debugging easier.
Now that the children_dirty flag works correctly, we can
rely on it to avoid redundant work. If children isn’t
dirty, we don’t need to recreate the BlockLayout
children:
class BlockLayout:
def layout(self):
if mode == "block":
if self.children_dirty:
# ...
self.children_dirty = FalseIf you add a print statement inside that inner-most
if, you’ll see console output every time
BlockLayout children are created. Try that out while
editing text: it shouldn’t happen at all, and editing will be slightly
smoother.
If you’ve heard Phil Karlton’s saying that “the two hardest problems in computer science are cache invalidation and naming things”, you know that managing more and more dirty flags creates increasing complexity. Phil worked at Netscape at one point (officially as “Principal Curmudgeon”) so I like to imagine him saying that quote while talking about layout invalidation.
Dirty flags like children_dirty are the traditional
approach to layout invalidation, but they have downsides. Using them
correctly means paying attention to the dependencies between fields and
knowing when each field is read from and written to. And it’s easy to
forget to check or set a dirty flag, which leads to hard-to-find bugs.
In our simple browser it could probably be done, but a real browser’s
layout system is much more complex, and mistakes become almost
impossible to avoid.
A better approach exists. First of all, let’s try to combine the dirty flag and the field it protects into a single object:
class ProtectedField:
def __init__(self):
self.value = None
self.dirty = TrueThat clarifies which dirty flag protects which field. Let’s replace
our existing dirty flag with a ProtectedField:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.children = ProtectedField()
# ...Next, let’s add methods for each step of the dirty flag life cycle.
I’ll say that we mark a protected field to set its dirty
flag:
class ProtectedField:
def mark(self):
if self.dirty: return
self.dirty = TrueNote the early return: marking an already dirty field doesn’t do
anything. That’ll become relevant later. Now call mark in
innerHTML_set and keypress:
class JSContext:
def innerHTML_set(self, handle, s, window_id):
# ...
obj.children.mark()
class Frame:
def keypress(self, char):
elif self.tab.focus and \
"contenteditable" in self.tab.focus.attributes:
# ...
obj.children.mark()Before “get”-ting a ProtectedField’s value,
let’s check the dirty flag:
class ProtectedField:
def get(self):
assert not self.dirty
return self.valueNow we can use get to read the children
field in layout and in lots of other places besides:
class BlockLayout:
def layout(self):
# ...
for child in self.children.get():
child.layout()
self.height = \
sum([child.height for child in self.children.get()])The nice thing about get is that it makes the dirty flag
operations automatic, and therefore impossible to forget. It also makes
the code a little nicer to read.
Finally, to reset the dirty flag, let’s make the caller pass in a new
value when “set”-ting the field. This guarantees that the
dirty flag and the value are updated together:
class ProtectedField:
def set(self, value):
self.value = value
self.dirty = FalseUnfortunately, using set will require a bit of
refactoring. For example, in BlockLayout, we’ll need to
build the children array in a local variable and then set
the children field at the end:
class BlockLayout:
def layout(self):
if mode == "block":
if self.children.dirty:
children = []
previous = None
for child in self.node.children:
next = BlockLayout(
child, self, previous, self.frame)
children.append(next)
previous = next
self.children.set(children)But the benefit is that set, much like get,
automates the dirty flag operations, making them hard to mess up. That
makes it possible to think about more complex and ambitious invalidation
algorithms in order to make layout faster.
Under-invalidation is the technical name for forgetting to set the dirty flag on a field when you change a dependency. It often causes a bug where a particular change needs to happen multiple times to finally “take”. In other words, this kind of bug creates accidental non-idempotency! These bugs are hard to find because they typically only show up if you make a very specific sequence of changes.
Let’s leverage the ProtectedField class to avoid
recreating all of the LineLayouts and their children every
time inline layout happens. It all starts here:
class BlockLayout:
def layout(self):
if mode == "block":
# ...
else:
self.children = []
self.new_line()
self.recurse(self.node)The new_line and recurse methods, and the
helpers they call like word, input,
iframe, image, and
add_inline_child, handle line wrapping: they check widths,
create new lines, and so on. We’d like to skip all that if the
children field isn’t dirty, but this will be a bit more
challenging than for block layout mode: lots of different fields are
read during line wrapping, and the children field depends
on all of them.
Converting all of those fields into ProtectedFields will
be a challenging project. We’ll take it bit by bit, starting with
zoom, which almost every method reads.
Zoom is initially set in DocumentLayout:
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.zoom = ProtectedField()
# ...
def layout(self, width, zoom):
# ...
self.zoom.set(zoom)
# ...Each BlockLayout also has its own zoom
field, which we can protect:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.zoom = ProtectedField()
# ...However, in BlockLayout, the zoom value
comes from its parent’s zoom field. We might be tempted to
write something like this:
class BlockLayout:
def layout(self):
parent_zoom = self.parent.zoom.get()
self.zoom.set(parent_zoom)
# ...However, recall that with dirty flags we must always think about
invalidating them (with mark), checking them (with
get), and resetting them (with set). We’ve
added get and set, but who marks the
zoom dirty flag?Without marking them when they change, we will incorrectly
skip too much layout work.
We mark a field’s dirty flag when its dependency changes. For
example, innerHTML_set and keypress change the
HTML tree, which the layout tree’s children field depends
on, so those handlers call mark on the
children field. Since a child’s zoom field
depends on its parents’ zoom field, we need to mark all the
children when the zoom field changes. So in
DocumentLayout, we have to do:
class DocumentLayout:
def layout(self, width, zoom):
# ...
self.zoom.set(zoom)
child.zoom.mark()
# ...Similarly, in BlockLayout, which has multiple children,
we must do:
class BlockLayout:
def layout(self):
# ...
for child in self.children.get():
child.zoom.mark()But now we’re back to manually calling methods and trying to make
sure we don’t forget a call. What we need is something seamless:
set-ting a field should automatically mark all the fields
that depend on it.
To do that, each ProtectedField will need to track all
fields that depend on it, called its invalidations:
class ProtectedField:
def __init__(self):
# ...
self.invalidations = set()For example, we can add the child’s zoom field to its
parent’s zoom field’s invalidations:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.parent.zoom.invalidations.add(self.zoom)Then, to automate the mark call, let’s add a
notify method to mark each invalidation:
class ProtectedField:
def notify(self):
for field in self.invalidations:
field.mark()Then set can automatically call notify:
class ProtectedField:
def set(self, value):
self.notify()
self.value = value
self.dirty = FalseThat’s progress, but it’s still possible to forget to add the
invalidation in the first place. We can automate it a little further.
Think: why does the child’s zoom need to depend on
its parent’s? It’s because we get the parent’s
zoom when computing the child’s. So adding the invalidation
can happen as part of get! Let’s make a variant of
get called read with a notify
parameter for the field to invalidate if the field being read
changes:
class ProtectedField:
def read(self, notify):
self.invalidations.add(notify)
return self.get()Now the zoom computation just needs to use
read, and all of the marking and dependency logic will be
handled automatically:
class BlockLayout:
def layout(self):
parent_zoom = self.parent.zoom.read(notify=self.zoom)
self.zoom.set(parent_zoom)In fact, this pattern where we just copy our parent’s value is pretty common, so let’s add a shortcut for it:
class ProtectedField:
def copy(self, field):
self.set(field.read(notify=self))
class BlockLayout:
def layout(self):
self.zoom.copy(self.parent.zoom)
# ...BlockLayout also reads from the zoom field
inside the input, image, iframe,
word, and add_inline_child methods, which are
all part of computing the children field. In those methods,
we can use read to both get the zoom value and also
invalidate the children field if the zoom value ever
changes:
class BlockLayout:
def input(self, node):
zoom = self.zoom.read(notify=self.children)
# ...Do the same in each of the other methods mentioned above. Also, go
and protect the zoom field on every other layout object
type (there are now quite a few!) using copy in place of
writes and read in place of gets. Run your
browser and make sure that nothing crashes, even when you increase or
decrease the zoom level, to make sure you got it right.
Now—protecting the zoom field did not speed our browser
up. We’re still copying the zoom level around, plus we’re now doing some
extra work checking dirty flags and updating invalidations. But
protecting the zoom field means we can invalidate
children, and other fields that depend on it, when the zoom
level changes, which will help tell us when we have to rebuild
LineLayout and TextLayout elements.
Real browsers don’t use automatic dependency-tracking like
ProtectedField (for now at least). One reason is
performance: ProtectedField adds lots of objects and method
calls, and it’s easy to accidentally make performance worse by
over-using it. It’s also possible to create cascading work by
invalidating too many protected fields. Finally, most browser engine
code bases have a lot of historical code, and it takes a lot of time to
refactor them to use new approaches.
Another field that line wrapping depends on is width.
Let’s convert that to a ProtectedField, using the new
read method along the way. Like zoom,
width is initially set in DocumentLayout:
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.width = ProtectedField()
# ...
def layout(self, width, zoom):
# ...
self.width.set(width - 2 * dpx(HSTEP, zoom))
# ...Then, BlockLayout copies it from the parent:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.zoom = ProtectedField()
# ...
def layout(self):
# ...
self.width.copy(self.parent.width)
# ...The width field is read during line wrapping. For
example, add_inline_child needs it to determine whether to
add a new line. We’ll use read to set up that
dependency:
class BlockLayout:
def add_inline_child(self, node, w, child_class,
frame, word=None):
width = self.width.read(notify=self.children)
if self.cursor_x + w > width:
self.new_line()
# ...While we’re here, note that the decision for whether or not to add a
new line also depends on w, which is an input to
add_inline_child. If you look through
add_inline_child’s callers, you’ll see that most of the
time, this argument just depends on zoom, but in
word it depends on a font object:
class BlockLayout:
def word(self, node, word):
zoom = self.zoom.read(notify=self.children)
node_font = font(node.style, zoom)
w = node_font.measureText(word)
self.add_inline_child(
node, w, TextLayout, self.frame, word)Note that the font depends on the node’s style, which
can change, for example via the style_set function. To
handle this, we’ll need to protect style:
class Element:
def __init__(self, tag, attributes, parent):
# ...
self.style = ProtectedField()
# ...
class Text:
def __init__(self, text, parent):
# ...
self.style = ProtectedField()
# ...The style field is computed in the style
method, which computes a new style dictionary over multiple
phases. Let’s build that new dictionary in a local variable, and
set it at the end:
def style(node, rules, frame):
old_style = node.style.value
new_style = {}
# ...
node.style.set(new_style)
for child in node.children:
style(child, rules, frame)Inside style, one code path reads from the parent node’s
style. We need to mark dependencies in these cases:
def style(node, rules, frame):
for property, default_value in INHERITED_PROPERTIES.items():
if node.parent:
parent_style = node.parent.style.read(notify=node.style)
new_style[property] = parent_style[property]
else:
new_style[property] = default_valueThen style_set can mark the style
field:We would ideally
make the style attribute a protected field, and have the
style field depend on it, but I’m taking a short-cut in the
interest of simplicity.
class JSContext:
def style_set(self, handle, s, window_id):
# ...
elt.style.mark()Finally, in word (and also in similar code in
add_inline_child) we can depend on the style
field:
class BlockLayout:
def word(self, node, word):
# ...
style = self.children.read(node.style)
node_font = font(style, zoom)
# ...Make sure all other uses of the style field use either
read or get; it should be pretty clear which
is which.
We’ve now protected all of the fields read during line wrapping. That
means the children field’s dirty flag now correctly tracks
whether line-wrapping can be skipped. Let’s make use of that:
class BlockLayout:
def layout(self):
# ...
if mode == "block":
if self.children.dirty:
# ...
else:
if self.children.dirty:
# ...We also need to make sure we now only modify children
via set. That’s a problem for add_inline_child
and new_line, which currently append to the
children field. There are a couple of possible fixes, but
in the interests of expediency,Perhaps the nicest design would thread a local
children variable through all of the methods involved in
line layout, similar to tree_to_list. I’m
going to use a second, unprotected field, temp_children, to
build the list of children, and then set it as the new
value of the children field at the end:
class BlockLayout:
def layout(self):
# ...
if mode == "block":
# ...
else:
if self.children.dirty:
self.temp_children = []
self.new_line()
self.recurse(self.node)
self.children.set(self.temp_children)
self.temp_children = NoneNote that I reset temp_children once we’re done with it,
to make sure that no other part of the code accidentally uses it. This
way, new_line can modify temp_children, which
will eventually become the value of children:
class BlockLayout:
def new_line(self):
self.previous_word = None
self.cursor_x = 0
last_line = self.temp_children[-1] \
if self.temp_children else None
new_line = LineLayout(self.node, self, last_line)
self.temp_children.append(new_line)You’ll want to do something similar in
add_inline_child:
class BlockLayout:
def add_inline_child(self, node, w, child_class,
frame, word=None):
# ...
line = self.temp_children[-1]
# ...Thanks to these fixes, our browser now avoids rebuilding any part of
the layout tree unless it changes, and that should make re-layout
somewhat faster. If you’ve been going through and adding the appropriate
read and get calls, your browser should be
close to working. There’s one tricky case: tree_to_list,
which might deal with both protected and unprotected
children fields. I fixed this with a type test:
def tree_to_list(tree, list):
# ...
children = tree.children
if isinstance(children, ProtectedField):
children = children.get()
for child in children:
tree_to_list(child, list)
# ...With all of these changes made, your browser should work again, and it should now skip line layout for most elements.
Note that we have quite a few protected fields now, but we only skip
recomputing children based on dirty flags. That’s because
recomputing children is slow, but most other fields are
really fast to compute. Checking dirty flags takes time and adds code
clutter, so we only want to do it when it’s worth it.
In real browsers, the layout phase is sometimes split in two, first constructing a layout tree and then a separate fragment tree.This book doesn’t separate out the fragment tree because our layout algorithm is simple enough not to need it. In Chromium, the fragment tree is immutable, and invalidation is done by comparing the previous and new fragment trees instead of by using dirty flags, though the effect of that is pretty similar to what this book describes.
At this point, BlockLayout has a protected
width field, but other layout object types do not. Let’s
fix that, because we’ll need it later. LineLayout is pretty
easy:
class LineLayout:
def __init__(self, node, parent, previous):
# ...
self.width = ProtectedField()
# ...
def layout(self):
# ...
self.width.copy(self.parent.width)
# ...In TextLayout, we again need to handle font
(and hence have width depend on style):
class TextLayout:
def __init__(self, node, word, parent, previous):
# ...
self.width = ProtectedField()
# ...
def layout(self):
# ...
style = self.width.read(self.node.style)
zoom = self.width.read(self.zoom)
self.font = font(style, zoom)
self.width.set(self.font.measureText(self.word))
# ...In EmbedLayout, we just need to protect the
width field:
class EmbedLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.width = ProtectedField()
# ...There’s also a reference to width in the
layout method for computing x positions. For
now you can just use get here.
Finally, there are the various types of replaced content. In
InputLayout, the width only depends on the zoom level:
class InputLayout(EmbedLayout):
def layout(self):
# ...
zoom = self.zoom.read(notify=self.width)
self.width.set(dpx(INPUT_WIDTH_PX, zoom))
# ...IframeLayout and ImageLayout are very
similar, with the width depending on the zoom level and also the
element’s width and height attributes. So,
we’ll need to invalidate the width field if those
attributes are changed from JavaScript:
class JSContext:
def setAttribute(self, handle, attr, value, window_id):
# ...
obj = elt.layout_object
if isinstance(obj, IframeLayout) or \
isinstance(obj, ImageLayout):
if attr == "width" or attr == "height":
obj.width.mark()Otherwise, IframeLayout and ImageLayout are
handled just like InputLayout. Search your code to make
sure you’re always interacting with width via methods like
get and read, and check that your browser
works, including testing user interactions like
contenteditable.
The ProtectedField class defined here is a type of monad,
a programming pattern used in programming languages like Haskell. In brief, monads describe
ways of connecting steps in a computation, though the specifics are famously
confusing. Luckily, in this chapter we don’t really need to think
about monads in general, just ProtectedField.
While we’re here, let’s take a moment to protect all of the other
layout fields, including x, y, and
height. Once we’ve done that, we’ll be ready to talk about
speeding up layout even further by skipping unnecessary traversals.
As with width, let’s start with
DocumentLayout and BlockLayout. First,
x and y positions. In
DocumentLayout, just use set:
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.x = ProtectedField()
self.y = ProtectedField()
# ...
def layout(self, width, zoom):
# ...
self.x.set(dpx(HSTEP, zoom))
self.y.set(dpx(VSTEP, zoom))
# ...A BlockLayout’s x position is just its
parent’s x position, so we can just copy it
over:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.x = ProtectedField()
# ...
def layout(self):
# ...
self.x.copy(self.parent.x)
# ...However, the y position sometimes refers to the
previous sibling:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.y = ProtectedField()
def layout(self):
# ...
if self.previous:
prev_y = self.previous.y.read(notify=self.y)
prev_height = self.previous.height.read(notify=self.y)
self.y.set(prev_y + prev_height)
else:
self.y.copy(self.parent.y)
# ...Let’s also do heights. For DocumentLayout,
we just read the child’s height:
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.height = ProtectedField()
# ...
def layout(self, width, zoom):
# ...
self.height.copy(child.height)BlockLayout is similar, except it loops over multiple
children:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.height = ProtectedField()
# ...
def layout(self):
# ...
children = self.children.read(notify=self.height)
new_height = sum([
child.height.read(notify=self.height)
for child in children
])
self.height.set(new_height)Note that in this last code block, we first read the
children field, then iterate over the list of children and
read each of their height fields. The
height field, unlike the previous layout fields, depends on
the children’s fields, not the parent’s (see Figure 2).
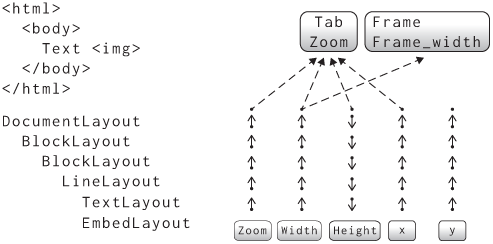
So that’s all the layout fields on BlockLayout and
DocumentLayout. Do go through and fix up these layout
types’ paint methods (and also the DrawCursor
helper)—but note that the browser won’t quite run right now, because the
BlockLayout assumes its children’s height
fields are protected, but if those fields are LineLayouts
they aren’t. Let’s get to that next.
Dirty flags aren’t the only way to achieve incremental performance; another option is to keep track of deltas. For example, in the Adapton project, each computation that converts inputs to outputs can also convert input deltas to output deltas. Operational Transform, the collaboration technology behind Google Docs, also works using this principle, as does differential dataflow in databases. However, dirty flags can be implemented with much less memory overhead, which makes them a better fit in browsers.
We need to protect LineLayouts’,
TextLayouts’, and EmbedLayouts’ fields too,
and their layout methods work a little differently. Yes,
each of these layout objects has x, y, and
height fields, but they also compute font,
ascent, and descent fields that are used by
other layout objects. We’ll have to protect all of these. Since we now
have quite a bit of ProtectedField experience, we’ll do all
the fields in one go.
Let’s start with TextLayout:
class TextLayout:
def __init__(self, node, word, parent, previous):
# ...
self.x = ProtectedField()
self.y = ProtectedField()
self.height = ProtectedField()
self.font = ProtectedField()
self.ascent = ProtectedField()
self.descent = ProtectedField()
# ...We’ll need to compute these fields in layout. All of the
font-related ones are fairly straightforward:
class TextLayout:
def layout(self):
# ...
zoom = self.zoom.read(notify=self.font)
style = self.node.style.read(notify=self.font)
self.font.set(font(style, zoom))
f = self.font.read(notify=self.width)
self.width.set(f.measureText(self.word))
f = self.font.read(notify=self.ascent)
self.ascent.set(f.getMetrics().fAscent * 1.25)
f = self.font.read(notify=self.descent)
self.descent.set(f.getMetrics().fDescent * 1.25)
f = self.font.read(notify=self.height)
self.height.set(linespace(f) * 1.25)Note that I’ve changed width to read the
font field instead of directly reading zoom
and style. It does look a bit odd to compute
f repeatedly, but remember that each of those
read calls establishes a dependency for one layout field
upon another. I like to think of each f as being scoped to
its field’s computation.
We also need to compute the x position of a
TextLayout. That can use the previous sibling’s font,
x position, and width:
class TextLayout:
def layout(self):
# ...
if self.previous:
prev_x = self.previous.x.read(notify=self.x)
prev_font = self.previous.font.read(notify=self.x)
prev_width = self.previous.width.read(notify=self.x)
self.x.set(
prev_x + prev_font.measureText(' ') + prev_width)
else:
self.x.copy(self.parent.x)EmbedLayout is basically identical. As for its
subclasses, here’s InputLayout:
class InputLayout(EmbedLayout):
def layout(self):
super().layout()
zoom = self.zoom.read(notify=self.width)
self.width.set(dpx(INPUT_WIDTH_PX, zoom))
font = self.font.read(notify=self.height)
self.height.set(linespace(font))
height = self.height.read(notify=self.ascent)
self.ascent.set(-height)
self.descent.set(0)And here’s ImageLayout; it has an
img_height field, which I’m going to treat as an
intermediate step in computing height and not protect:
class ImageLayout(EmbedLayout):
def layout(self):
# ...
font = self.font.read(notify=self.height)
self.height.set(max(self.img_height, linespace(font)))
height = self.height.read(notify=self.ascent)
self.ascent.set(-height)
self.descent.set(0)Finally, here’s how IframeLayout computes its height,
which is straightforward:
class IframeLayout(EmbedLayout):
def layout(self):
# ...
zoom = self.zoom.read(notify=self.height)
if height_attr:
self.height.set(dpx(int(height_attr) + 2, zoom))
else:
self.height.set(dpx(IFRAME_HEIGHT_PX + 2, zoom))
# ...We also need to invalidate the height field if the
height attribute changes:
class JSContext:
def setAttribute(self, handle, attr, value, window_id):
if isinstance(obj, IframeLayout) or \
isinstance(obj, ImageLayout):
if attr == "width" or attr == "height":
# ...
obj.height.mark()So that covers all of the inline layout objects. All that’s left is
LineLayout. Here are x and y:
class LineLayout:
def __init__(self, node, parent, previous):
# ...
self.x = ProtectedField()
self.y = ProtectedField()
# ...
def layout(self):
# ...
self.x.copy(self.parent.x)
if self.previous:
prev_y = self.previous.y.read(notify=self.y)
prev_height = self.previous.height.read(notify=self.y)
self.y.set(prev_y + prev_height)
else:
self.y.copy(self.parent.y)
# ...However, height is a bit complicated: it computes the
maximum ascent and descent across all children and uses that to set the
height and the children’s y. I think the
simplest way to handle this code is to add ascent and
descent fields to the LineLayout to store the
maximum ascent and descent, and then have the height and
the children’s y field depend on those.
Let’s do that, starting with declaring the protected fields:
class LineLayout:
def __init__(self, node, parent, previous):
# ...
self.ascent = ProtectedField()
self.descent = ProtectedField()Then, in layout, we’ll first handle the case of no
children:
class LineLayout:
def layout(self):
# ...
if not self.children:
self.height.set(0)
returnNote that we don’t need to read the
children field because in LineLayout it isn’t
protected; it’s filled in by BlockLayout when the
LineLayout is created, and then never modified.
Next, let’s compute the maximum ascent and descent:
class LineLayout:
def layout(self):
# ...
self.ascent.set(max([
-child.ascent.read(notify=self.ascent)
for child in self.children
]))
self.descent.set(max([
child.descent.read(notify=self.descent)
for child in self.children
]))Next, we can recompute the y position of each child:
class LineLayout:
def layout(self):
# ...
for child in self.children:
new_y = self.y.read(notify=child.y)
new_y += self.ascent.read(notify=child.y)
new_y += child.ascent.read(notify=child.y)
child.y.set(new_y)Finally, we recompute the line’s height:
class LineLayout:
def layout(self):
# ...
max_ascent = self.ascent.read(notify=self.height)
max_descent = self.descent.read(notify=self.height)
self.height.set(max_ascent + max_descent)As a result of these changes, every layout object field is now
protected. Just like before, make sure all uses of these fields use
read and get and that your browser still runs,
including during contenteditable. You will likely now need
to fix a few uses of height and y inside
Frame and Tab, like for clamping scroll
offsets.
Just before writing this section, IThis is Chris speaking. spent weeks weeding out some under-invalidation bugs in Chrome’s accessibility code. At first, the bugs would only occur on certain overloaded automated test machines! It turns out that on those machines, the HTML parser would yieldIn a real browser, HTML parsing doesn’t happen in one go, but often is broken up into multiple event loop tasks. This leads to better web page loading performance, and is the reason you’ll often see web pages render only part of the HTML at first when loading large web pages (including this book!). more often, triggering different and incorrect rendering paths. Deep bugs like this take untold hours to track down, which is why it’s so important to use robust abstractions to avoid them in the first place.
We’ve got quite a number of layout fields now, so let’s see how much
invalidation is actually going on. Add a print statement
inside the set method on ProtectedFields to
see which fields are getting recomputed:
class ProtectedField:
def set(self, value):
if self.value != None:
print("Change", self)
self.notify()
self.value = value
self.dirty = FalseThe if check avoids printing during initial page layout,
so it will only show how well our invalidation optimizations are
working. The fewer prints you see, the fewer fields change and the more
work we should be able to skip.
Try editing some text with contenteditable on a large
web page (like this chapter)—you’ll see a screenful of output,
thousands of lines of printed nonsense. It’s a little hard to understand
why, so let’s add a nice printable form for
ProtectedFields, plus a new name parameter for
debugging purposes:Note
that I print the node, not the layout object, because layout objects’
printable forms print layout field values, which might be dirty and
unreadable.
class ProtectedField:
def __init__(self, obj, name):
self.obj = obj
self.name = name
# ...
def __repr__(self):
return "ProtectedField({}, {})".format(
self.obj.node if hasattr(self.obj, "node") else self.obj,
self.name)Name all of your ProtectedFields, like this:
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.zoom = ProtectedField(self, "zoom")
self.width = ProtectedField(self, "width")
self.height = ProtectedField(self, "height")
self.x = ProtectedField(self, "x")
self.y = ProtectedField(self, "y")If you look at your output again, you should now see two phases.
First, there’s a lot of style re-computation:
Change ProtectedField(<body>, style)
Change ProtectedField(<header>, style)
Change ProtectedField(<h1 class="title">, style)
Change ProtectedField('Reusing Previous Computations', style)
Change ProtectedField(<a href="...">, style)
Change ProtectedField('Twitter', style)
Change ProtectedField(' ·\n', style)
...Then, we recompute four layout fields repeatedly:
Change ProtectedField(<html lang="en-US" xml:lang="en-US">, zoom)
Change ProtectedField(<html lang="en-US" xml:lang="en-US">, zoom)
Change ProtectedField(<head>, zoom)
Change ProtectedField(<head>, children)
Change ProtectedField(<head>, height)
Change ProtectedField(<body>, zoom)
Change ProtectedField(<body>, y)
Change ProtectedField(<header>, zoom)
Change ProtectedField(<header>, y)
...Let’s fix these. First, let’s tackle style. The reason
style is being recomputed repeatedly is just that we
recompute it even if it isn’t dirty. Let’s skip if it’s not:
def style(node, rules, frame):
if node.style.dirty:
# ...
for child in node.children:
style(child, rules, frame)There should now be barely any style re-computation at all. But what
about those layout field re-computations? Why are those happening? Well,
the very first field being recomputed here is zoom, which
itself traces back to DocumentLayout:
class DocumentLayout:
def layout(self, width, zoom):
self.zoom.set(zoom)
# ...Every time we lay out the page, we set the zoom
parameter, and we have to do that because the user might have zoomed in
or out. But every time we set a field, that notifies every
dependant field. The combination of these two things means we are
recomputing the zoom field, and everything that depends on
zoom, on every frame.
What makes this all wasteful is that zoom usually
doesn’t change. So we should notify dependants only if the value didn’t
change:
class ProtectedField:
def set(self, value):
if value != self.value:
self.notify()
# ...This change is safe, because if the new value is the same as the old value, any downstream computations don’t actually need to change. This small tweak should reduce the number of field changes down to the minimum:
Change ProtectedField(<html lang="en-US" xml:lang="en-US">, zoom)
Change ProtectedField(<div class="demo" ...>, children)
Change ProtectedField(<div class="demo" ...>, height)All that’s happening here is recreating the
contenteditable element’s children (which we
have to do, to incorporate the new text) and checking that its
height didn’t change (necessary in case we wrapped onto
more lines).
Editing should also now feel snappier—about 0.6 seconds instead of the original 1.7 (see Figure 3). Better, but still not good:Trace here.

The caching and invalidation we’re doing in browser layout has analogs throughout computer science. For example, some databases use incremental view maintenance to cache and update the results of common queries as database entries are added or modified. Build systems like Make also attempt to recompile only changed objects, and spreadsheets attempt to recompute only formulas that might have changed. The specific trade-offs browsers require may be unusual, but the problems and core algorithms are universal.
Now that all of the layout fields are protected, we can check if any of them need to be recomputed by checking their dirty bits. But to check all of those dirty bits, we’d need to visit every layout object, which can take a long time. Instead, we should use dirty bits to minimize the number of layout objects we need to visit.
The basic idea revolves around the question: do we even need to call
layout on a given node? The layout method does
three things: create child layout objects, compute layout properties,
and recurse into more calls to layout. Those steps can be
skipped if:
children field isn’t dirty;layout.There’s no dirty flag yet for the last condition, so let’s add one.
I’ll call it has_dirty_descendants because it tracks
whether any descendant has a dirty ProtectedField:In some code bases, you will
see these called ancestor dirty flags instead. It’s the same
thing, just following the flow of dirty bits instead of the flow of
control.
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.has_dirty_descendants = FalseAdd this to every other kind of layout object, too.
Now we need to set the has_dirty_descendants flag if any
dirty flag is set. We can do that with an additional (and optionalIt’s optional because only
ProtectedFields on layout objects need this
feature.) parent parameter to a
ProtectedField.
class ProtectedField:
def __init__(self, obj, name, parent=None):
# ...
self.parent = parentMake sure to pass this parameter for each ProtectedField
in each layout object type. Here’s BlockLayout, for
example:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.children = ProtectedField(self, "children", self.parent)
self.zoom = ProtectedField(self, "zoom", self.parent)
self.width = ProtectedField(self, "width", self.parent)
self.height = ProtectedField(self, "height", self.parent)
self.x = ProtectedField(self, "x", self.parent)
self.y = ProtectedField(self, "y", self.parent)Then, whenever mark or notify is called, we
set the descendant bits by walking the parent chain:
class ProtectedField:
def set_ancestor_dirty_bits(self):
parent = self.parent
while parent and not parent.has_dirty_descendants:
parent.has_dirty_descendants = True
parent = parent.parent
def mark(self):
# ...
self.set_ancestor_dirty_bits()Note that the while loop exits early if the descendants
bit is already set. That’s because whoever set that bit already
set all the ancestors’ descendant dirty bits.This optimization is important
in real browsers. Without it, repeatedly invalidating the same object
would walk up the tree to the root repeatedly, violating the principle
of incremental performance.
We’ll need to clear the descendant bits after
layout:
class BlockLayout:
def layout(self):
# ...
for child in self.children.get():
child.layout()
self.has_dirty_descendants = False Now that we have descendant dirty flags, let’s use them to skip
layout, including recursive calls:
class BlockLayout:
def layout(self):
if not self.layout_needed(): return
# ...Here, the layout_needed method just checks all of the
dirty bits:
class BlockLayout:
def layout_needed(self):
if self.zoom.dirty: return True
if self.width.dirty: return True
if self.height.dirty: return True
if self.x.dirty: return True
if self.y.dirty: return True
if self.children.dirty: return True
if self.has_dirty_descendants: return True
return FalseDo the same for every other type of layout object. In
DocumentLayout, you do need to be a little careful, since
it receives the frame width and zoom level as an argument; you have to
mark those fields of DocumentLayout if the
corresponding Frame variables change:We need to mark the root
layout object’s width because the frame_width
is passed into DocumentLayout’s layout method
as the width parameter. We could have protected the
frame_width field instead, and then this mark
would happen automatically; I’m skipping that for expediency, but it
would have been a bit safer.
class IframeLayout(EmbedLayout):
def layout(self):
if self.node.frame and self.node.frame.loaded:
# ...
self.node.frame.document.width.mark()The zoom level changes in Tab:
class Tab:
def zoom_by(self, increment):
# ...
for id, frame in self.window_id_to_frame.items():
frame.document.zoom.mark()
def reset_zoom(self):
# ...
for id, frame in self.window_id_to_frame.items():
frame.document.zoom.mark()Skipping unneeded layout methods should provide a
noticable speed bump, with small layouts now taking about 7 ms to update
layout and editing now substantially smoother.It might also be pretty laggy
on large pages due to the composite–raster–draw cycle being fairly slow,
depending on which exercises you implemented in Chapter
13.Trace
here.

However, Figure 4 shows that paint is still slow, and
render overall is still about 230 ms. Making a browser fast
requires optimizing everything! I won’t implement it, but paint can be
made a lot faster too—see Exercise 16-10.
ProtectedField is similar to the observer
pattern, where one piece of code runs a callback when a piece of
state changes. This pattern is common
in UI frameworks. Usually these observers eagerly recompute
dependent results, but our callbacks—mark and
notify—simply set a dirty bit to be cleaned up later. That
means our invalidation algorithm is a kind of lazy
observer. Laziness helps performance by batching updates.
Unfortunately, in the process of adding invalidation, we have
inadvertently broken smooth animations. Here’s the basic issue: suppose
an element’s opacity or transform property
changes, for example through JavaScript. That property isn’t
layout-inducing, so it should be animated entirely through
compositing. However, changing any style property invalidates the
Element’s style field, and that in turn
invalidates the children field, causing the layout tree to
be rebuilt. That’s no good.
Ultimately the core problem here is over-invalidation caused
by ProtectedFields that are too coarse-grained. The
children field, for example, doesn’t depend on the whole
style dictionary, just a few font-related fields in it. We
need style to be a dictionary of
ProtectedFields, not a ProtectedField of a
dictionary:
class Element:
def __init__(self, tag, attributes, parent):
# ...
self.style = dict([
(property, ProtectedField(self, property))
for property in CSS_PROPERTIES
])
# ...Make the same change in Text. The
CSS_PROPERTIES dictionary contains each CSS property that
we support, plus their default value:
CSS_PROPERTIES = {
"font-size": "inherit", "font-weight": "inherit",
"font-style": "inherit", "color": "inherit",
"opacity": "1.0", "transition": "",
"transform": "none", "mix-blend-mode": None,
"border-radius": "0px", "overflow": "visible",
"outline": "none", "background-color": "transparent",
"image-rendering": "auto",
}When setting the style property from JavaScript, I’ll
invalidate all of the fields by calling a new dirty_style
function:
def dirty_style(node):
for property, value in node.style.items():
value.mark()
class JSContext:
def style_set(self, handle, s, window_id):
# ...
dirty_style(elt)
# ...But that’s not all. There is also other code that invalidates style,
in particular code that can affect a pseudo-class such as
:focus.
class Frame:
def focus_element(self, node):
# ...
if self.tab.focus:
# ...
dirty_style(self.tab.focus)
if node:
#...
dirty_style(node)Similarly, in style, we will need to recompute a node’s
style if any of their style properties are dirty:
def style(node, rules, frame):
needs_style = any([field.dirty for field in node.style.values()])
if needs_style:
# ...
for child in node.children:
style(child, rules, frame)To match the existing code, I’ll make old_style and
new_style just map properties to values:
def style(node, rules, frame):
if needs_style:
old_style = dict([
(property, field.value)
for property, field in node.style.items()
])
new_style = CSS_PROPERTIES.copy()
# ...Then, when we resolve inheritance, we specifically have one field of our style depend on one field of the parent’s style:
def style(node, rules, frame):
if needs_style:
for property, default_value in INHERITED_PROPERTIES.items():
if node.parent:
parent_field = node.parent.style[property]
parent_value = \
parent_field.read(notify=node.style[property])
new_style[property] = parent_valueLikewise when resolving percentage font sizes:
def style(node, rules, frame):
if needs_style:
if new_style["font-size"].endswith("%"):
if node.parent:
parent_field = node.parent.style["font-size"]
parent_font_size = \
parent_field.read(notify=node.style["font-size"])Then, once the new_style is all computed, we
individually set every field of the node’s style:
def style(node, rules, frame):
if needs_style:
# ...
for property, field in node.style.items():
field.set(new_style[property])Now we just need to update the rest of the browser to use the
granular style fields. Mostly, this means replacing
style.get()[property] with
style[property].get():
def paint_visual_effects(node, cmds, rect):
opacity = float(node.style["opacity"].get())
blend_mode = node.style["mix-blend-mode"].get()
translation = parse_transform(node.style["transform"].get())
if node.style["overflow"].get() == "clip":
border_radius = float(node.style["border-radius"].get()[:-2])
# ...
# ...However, the font method needs a little bit of work.
Until now, we’ve read the node’s style and passed that to
font:
class BlockLayout:
def word(self, node, word):
zoom = self.children.read(self.zoom)
style = self.children.read(node.style)
node_font = font(style, zoom)
# ...That won’t work anymore, because now we need to read three different
properties of style. To keep things compact, I’m going to
rewrite font to pass in the field to invalidate as an
argument:
def font(css_style, zoom, notify):
weight = css_style['font-weight'].read(notify)
style = css_style['font-style'].read(notify)
try:
size = float(css_style['font-size'].read(notify)[:-2]) * 0.75
except:
size = 16
font_size = dpx(size, zoom)
return get_font(font_size, weight, style)Now we can simply pass self.children in for the
notify parameter when requesting a font during line
breaking:
class BlockLayout:
def word(self, node, word):
zoom = self.zoom.read(notify=self.children)
node_font = font(node.style, zoom, notify=self.children)
# ...Likewise, we pass in the font field if that’s what we’re
computing:
class TextLayout:
def layout(self):
if self.font.dirty:
zoom = self.zoom.read(notify=self.font)
self.font.set(font(
self.node.style, zoom, notify=self.font))Make sure to update all other uses of the font method to
this new interface. This “destination-passing style” is a common way to
add invalidation to helper methods.
Finally, now that we’ve added granular invalidation to
style, we can invalidate just the animating property when
handling animations:
class Tab:
def run_animation_frame(self, scroll):
for (window_id, frame) in self.window_id_to_frame.items():
for node in tree_to_list(frame.nodes, []):
for (property_name, animation) in \
node.animations.items():
value = animation.animate()
if value:
node.style[property_name].set(value)
# ...When a property like opacity or transform
is changed, it won’t invalidate any layout fields (because these
properties don’t affect any layout fields) and so animations will once
again skip layout entirely.
CSS styles depend on which elements a selector matches, and as the
page changes, that may also need to be invalidated.Our browser supports so few
CSS selectors and so few DOM APIs that it wouldn’t make sense to
implement such an advanced invalidation technique, but for real browsers
it is quite important. Browsers have clever algorithms to
avoid redoing selector matching for every selector on the page. For
example, Chromium constructs invalidation
sets for each selector, which tell it which selector-element
matches to recheck. New selectors such as :has() require more
complicated invalidation strategies, but this complexity is
necessary for fast re-styles.
Layout is now pretty fast and correct thanks to the
ProtectedField abstraction. However, because most of our
dependencies are established implicitly, by read, it’s hard
to tell which fields will ultimately get invalidated from any given
operation. That makes it hard to understand which operations are fast
and which are slow, especially as we add new style and layout features.
This auditability concern happens in real browsers, too. After
all, real browsers are millions, not thousands, of lines long, and
support thousands of CSS properties. Their dependency graphs are
dramatically more complex than our browser’s.
We’d therefore like to make it easier to see the dependency graph, though see Figure 5 for an idea of the scale of the task. And along the way we can centralize invariants about the shape of that graph. That will harden our browser against accidental bugs in the future and also improve performance.
An easy first step is explicitly listing the dependencies of each
ProtectedField. We can make this an optional constructor
parameter:
class ProtectedField:
def __init__(self, obj, name, parent=None, dependencies=None):
# ...
if dependencies != None:
for dependency in dependencies:
dependency.invalidations.add(self)Moreover, if the dependencies are passed in the constructor, we can
“freeze” the ProtectedField, so that read no
longer adds new dependencies, just checks that they were declared:
class ProtectedField:
def __init__(self, obj, name, parent=None, dependencies=None):
# ...
self.frozen_dependencies = (dependencies != None)
if dependencies != None:
for dependency in dependencies:
dependency.invalidations.add(self)
def read(self, notify):
if notify.frozen_dependencies:
assert notify in self.invalidations
else:
self.invalidations.add(notify)
return self.get()For example, in DocumentLayout, we can now be explicit
about the fact that its fields have no external dependencies, and thus
have to be marked explicitly:I didn’t even notice that
myself until I wrote this section!
class DocumentLayout:
def __init__(self, node, frame):
# ...
self.zoom = ProtectedField(self, "zoom", None, [])
self.width = ProtectedField(self, "width", None, [])
self.x = ProtectedField(self, "x", None, [])
self.y = ProtectedField(self, "y", None, [])
self.height = ProtectedField(self, "height")But note that height is missing the dependencies
parameter. A DocumentLayout’s height depends on its child’s
height, and that child doesn’t exist until layout is
called. “Downward” dependencies like this mean we can’t freeze every
ProtectedField when it’s constructed. But every protected
field we freeze makes the dependency graph easier to audit.
We can also freeze the zoom, width,
x, and y fields in BlockLayout.
For y, the dependencies differ based on whether or not the
layout object has a previous sibling:
class BlockLayout:
def __init__(self, node, parent, previous, frame):
# ...
if self.previous:
y_dependencies = [self.previous.y, self.previous.height]
else:
y_dependencies = [self.parent.y]
self.y = ProtectedField(
self, "y", self.parent, y_dependencies)
# ...We can’t freeze height for BlockLayout, for
the same reason as DocumentLayout, in the constructor. But
we can freeze it as soon as the children field is
computed. Let’s add a set_dependencies method to do
that:This is dynamic,
just like calls to read, but at least we’re centralizing
dependencies in one place. Plus, listing the dependencies explicitly and
then checking them later is a kind of defense
in depth against invalidation bugs.
class ProtectedField:
def set_dependencies(self, dependencies):
for dependency in dependencies:
dependency.invalidations.add(self)
self.frozen_dependencies = TrueNow we can freeze height in
DocumentLayout:
class DocumentLayout:
def layout(self, width, zoom):
if not self.children:
child = BlockLayout(self.node, self, None, self.frame)
self.height.set_dependencies([child.height])Similarly, in BlockLayout:
class BlockLayout:
def layout(self):
# ...
if mode == "block":
if self.children.dirty:
# ...
self.children.set(children)
height_dependencies = \
[child.height for child in children]
height_dependencies.append(self.children)
self.height.set_dependencies(height_dependencies)
else:
if self.children.dirty:
# ...
self.children.set(self.temp_children)
height_dependencies = \
[child.height for child in self.temp_children]
height_dependencies.append(self.children)
self.height.set_dependencies(height_dependencies)The other layout objects can also freeze their fields. In
TextLayout, EmbedLayout, and its subclasses we
can freeze everything:
class TextLayout:
def __init__(self, node, word, parent, previous):
# ...
self.zoom = ProtectedField(self, "zoom", self.parent,
[self.parent.zoom])
self.font = ProtectedField(self, "font", self.parent,
[self.zoom,
self.node.style['font-weight'],
self.node.style['font-style'],
self.node.style['font-size']])
self.width = ProtectedField(self, "width", self.parent,
[self.font])
self.height = ProtectedField(self, "height", self.parent,
[self.font])
self.ascent = ProtectedField(self, "ascent", self.parent,
[self.font])
self.descent = ProtectedField(self, "descent", self.parent,
[self.font])
if self.previous:
x_dependencies = [self.previous.x, self.previous.font,
self.previous.width]
else:
x_dependencies = [self.parent.x]
self.x = ProtectedField(self, "x", self.parent,
x_dependencies)
self.y = ProtectedField(self, "y", self.parent,
[self.ascent, self.parent.y, self.parent.ascent])In LineLayout, due to the somewhat complicated way a
line is created and then laid out, we need to delay freezing
ascent and descent until the first time
layout is called:
class LineLayout:
def __init__(self, node, parent, previous):
# ...
self.initialized_fields = False
self.ascent = ProtectedField(self, "ascent", self.parent)
self.descent = ProtectedField(self, "descent", self.parent)
# ...
def layout(self):
if not self.initialized_fields:
self.ascent.set_dependencies(
[child.ascent for child in self.children])
self.descent.set_dependencies(
[child.descent for child in self.children])
self.initialized_fields = True
# ...The last layout class is EmbedLayout. The dependencies
there are straightforward except for two things: first, just like for
TextLayout, x depends on the previous
x if present, and second, height depends on
width because of aspect ratios:
class EmbedLayout:
def __init__(self, node, parent, previous, frame):
# ...
self.zoom = ProtectedField(self, "zoom", self.parent,
[self.parent.zoom])
self.font = ProtectedField(self, "font", self.parent,
[self.zoom,
self.node.style['font-weight'],
self.node.style['font-style'],
self.node.style['font-size']])
self.width = ProtectedField(self, "width", self.parent,
[self.zoom])
self.height = ProtectedField(self, "height", self.parent,
[self.zoom, self.font, self.width])
self.ascent = ProtectedField(self, "ascent", self.parent,
[self.height])
self.descent = ProtectedField(
self, "descent", self.parent, [])
if self.previous:
x_dependencies = \
[self.previous.x, self.previous.font,
self.previous.width]
else:
x_dependencies = [self.parent.x]
self.x = ProtectedField(
self, "x", self.parent, x_dependencies)
self.y = ProtectedField(self, "y", self.parent,
[self.ascent,self.parent.y, self.parent.ascent])We can even freeze all of the style fields! The only complication is
that innerHTML changes an element’s parent, so let’s create
the style dictionary dynamically. Initialize it to None in
the constructor:
class Element:
def __init__(self, tag, attributes, parent):
# ...
self.style = None
class Text:
def __init__(self, text, parent):
# ...
self.style = NoneThen set it the first time style is called:
def style(node, rules, frame):
if not node.style:
init_style(node)Inside init_style, we need to freeze the dependencies of
each style field. That’s easy: only inherited fields have any
dependencies:
def init_style(node):
node.style = dict([
(property, ProtectedField(node, property, None,
[node.parent.style[property]] \
if node.parent and \
property in INHERITED_PROPERTIES \
else []))
for property in CSS_PROPERTIES
])By freezing every layout and style field, except
children, we can get a good sense of our browser’s
dependency graph just by looking at layout object type constructors.
That’s nice, and helps us avoid cycles and long dependency chains as we
add more style and layout features.
But to obtain maximum performance, the kind you would need for a real
browser, there’s an additional benefit. All these fancy
ProtectedFields add a lot of overhead, mostly because they
take up more memory and require more function calls. In fact, this
chapter likely made your browser quite a bit slower on an
initial page load.For me, it’s about twice as slow. Some of
that can be improved by skipping asserts,If you run Python with the
-O command-line flag, Python will automatically skip
asserts. but it’s definitely not ideal.
Luckily, techniques like compile-time code generation and macros can
be used to turn ProtectedField objects into straight-line
code behind the scenes. Setting a particular ProtectedField
can set the dirty bits on statically known invalidations, the dirty bits
can be inlined into the layout objects, and the read
function can check that the dependency was declared at compile
time.Real browsers pull
tricks like that all the time, in order to be super fast but still
maintainable and readable. For example, Chromium has a fancy way of generating
optimized code for all of the style properties. Such
techniques are beyond the scope of this book, but I’ve left exploring it
to an advanced exercise.
Real browsers also use assertions to catch bugs, much like the
ProtectedField abstraction in this chapter. But to avoid
slowing down the browser for users, non-essential assertions are
“compiled out” in the release build, which is what end-users
run. The debug build is what browser engineers use when
debugging or developing new features, and also in automated tests. Debug
builds also compile in debugging features like sanitizers,
while release builds instead use heavyweight optimizations like
profile-guided optimization.
This chapter introduces the concept of partial style and layout through optimized cache invalidation. The main takeaways are:
ProtectedField.Click here to try this chapter’s browser.
The complete set of functions, classes, and methods in our browser should now look something like this:
COOKIE_JAR
class URL:
def __init__(url)
def request(referrer, payload)
def resolve(url)
def origin()
def __str__()
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
def tree_to_list(tree, list)
def is_focusable(node)
def get_tabindex(node)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
class CSSParser:
def __init__(s)
def whitespace()
def literal(literal)
def word()
def ignore_until(chars)
def pair(until)
def selector()
def body()
def parse()
def until_chars(chars)
def simple_selector()
def media_query()
class TagSelector:
def __init__(tag)
def matches(node)
class DescendantSelector:
def __init__(ancestor, descendant)
def matches(node)
class PseudoclassSelector:
def __init__(pseudoclass, base)
def matches(node)
FONTS
def get_font(size, weight, style)
def font(css_style, zoom, notify)
def linespace(font)
NAMED_COLORS
def parse_color(color)
def parse_blend_mode(blend_mode_str)
def parse_transition(value)
def parse_transform(transform_str)
def parse_outline(outline_str)
def parse_image_rendering(quality)
REFRESH_RATE_SEC
class MeasureTime:
def __init__()
def time(name)
def stop(name)
def finish()
class Task:
def __init__(task_code)
def run()
class TaskRunner:
def __init__(tab)
def schedule_task(task)
def set_needs_quit()
def clear_pending_tasks()
def start_thread()
def run()
def handle_quit()
DEFAULT_STYLE_SHEET
CSS_PROPERTIES
INHERITED_PROPERTIES
def init_style(node)
def style(node, rules, frame)
def cascade_priority(rule)
def diff_styles(old_style, new_style)
class NumericAnimation:
def __init__(old_value, new_value, num_frames)
def animate()
def dirty_style(node)
class ProtectedField:
def __init__(obj, name, parent, dependencies, invalidations)
def set_dependencies(dependencies)
def set_ancestor_dirty_bits()
def mark()
def notify()
def set(value)
def get()
def read(notify)
def copy(field)
def __repr__()
def dpx(css_px, zoom)
WIDTH, HEIGHT
HSTEP, VSTEP
INPUT_WIDTH_PX
IFRAME_WIDTH_PX, IFRAME_HEIGHT_PX
BLOCK_ELEMENTS
class DocumentLayout:
def __init__(node, frame)
def layout(width, zoom)
def should_paint()
def paint()
def paint_effects(cmds)
def layout_needed()
class BlockLayout:
def __init__(node, parent, previous, frame)
def layout_mode()
def layout()
def recurse(node)
def add_inline_child(node, w, child_class, frame, word)
def new_line()
def word(node, word)
def input(node)
def image(node)
def iframe(node)
def self_rect()
def should_paint()
def paint()
def paint_effects(cmds)
def layout_needed()
class LineLayout:
def __init__(node, parent, previous)
def layout()
def should_paint()
def paint()
def paint_effects(cmds)
def layout_needed()
class TextLayout:
def __init__(node, word, parent, previous)
def layout()
def should_paint()
def paint()
def paint_effects(cmds)
def self_rect()
def layout_needed()
class EmbedLayout:
def __init__(node, parent, previous, frame)
def layout()
def should_paint()
def layout_needed()
class InputLayout:
def __init__(node, parent, previous, frame)
def layout()
def paint()
def paint_effects(cmds)
def self_rect()
class ImageLayout:
def __init__(node, parent, previous, frame)
def layout()
def paint()
def paint_effects(cmds)
class IframeLayout:
def __init__(node, parent, previous, parent_frame)
def layout()
def paint()
def paint_effects(cmds)
BROKEN_IMAGE
class PaintCommand:
def __init__(rect)
class DrawText:
def __init__(x1, y1, text, font, color)
def execute(canvas)
class DrawRect:
def __init__(rect, color)
def execute(canvas)
class DrawRRect:
def __init__(rect, radius, color)
def execute(canvas)
class DrawLine:
def __init__(x1, y1, x2, y2, color, thickness)
def execute(canvas)
class DrawOutline:
def __init__(rect, color, thickness)
def execute(canvas)
class DrawCompositedLayer:
def __init__(composited_layer)
def execute(canvas)
class DrawImage:
def __init__(image, rect, quality)
def execute(canvas)
def DrawCursor(elt, offset)
class VisualEffect:
def __init__(rect, children, node)
class Blend:
def __init__(opacity, blend_mode, node, children)
def execute(canvas)
def map(rect)
def unmap(rect)
def clone(child)
class Transform:
def __init__(translation, rect, node, children)
def execute(canvas)
def map(rect)
def unmap(rect)
def clone(child)
def local_to_absolute(display_item, rect)
def absolute_bounds_for_obj(obj)
def absolute_to_local(display_item, rect)
def map_translation(rect, translation, reversed)
def paint_tree(layout_object, display_list)
def paint_visual_effects(node, cmds, rect)
def paint_outline(node, cmds, rect, zoom)
def add_parent_pointers(nodes, parent)
class CompositedLayer:
def __init__(skia_context, display_item)
def can_merge(display_item)
def add(display_item)
def composited_bounds()
def absolute_bounds()
def raster()
SPEECH_FILE
class AccessibilityNode:
def __init__(node, parent)
def compute_bounds()
def build()
def build_internal(child_node)
def contains_point(x, y)
def hit_test(x, y)
def map_to_parent(rect)
def absolute_bounds()
class FrameAccessibilityNode:
def __init__(node, parent)
def build()
def hit_test(x, y)
def map_to_parent(rect)
def speak_text(text)
EVENT_DISPATCH_JS
SETTIMEOUT_JS
XHR_ONLOAD_JS
POST_MESSAGE_DISPATCH_JS
RUNTIME_JS
class JSContext:
def __init__(tab, url_origin)
def run(script, code, window_id)
def add_window(frame)
def wrap(script, window_id)
def dispatch_event(type, elt, window_id)
def dispatch_post_message(message, window_id)
def dispatch_settimeout(handle, window_id)
def dispatch_xhr_onload(out, handle, window_id)
def dispatch_RAF(window_id)
def throw_if_cross_origin(frame)
def get_handle(elt)
def querySelectorAll(selector_text, window_id)
def getAttribute(handle, attr)
def setAttribute(handle, attr, value, window_id)
def innerHTML_set(handle, s, window_id)
def style_set(handle, s, window_id)
def XMLHttpRequest_send(...)
def setTimeout(handle, time, window_id)
def requestAnimationFrame()
def parent(window_id)
def postMessage(target_window_id, message, origin)
SCROLL_STEP
class Frame:
def __init__(tab, parent_frame, frame_element)
def allowed_request(url)
def load(url, payload)
def render()
def clamp_scroll(scroll)
def set_needs_render()
def set_needs_layout()
def advance_tab()
def focus_element(node)
def activate_element(elt)
def submit_form(elt)
def keypress(char)
def scrolldown()
def scroll_to(elt)
def click(x, y)
class Tab:
def __init__(browser, tab_height)
def load(url, payload)
def run_animation_frame(scroll)
def render()
def get_js(url)
def allowed_request(url)
def raster(canvas)
def clamp_scroll(scroll)
def set_needs_render()
def set_needs_layout()
def set_needs_paint()
def set_needs_render_all_frames()
def set_needs_accessibility()
def scrolldown()
def click(x, y)
def go_back()
def submit_form(elt)
def keypress(char)
def focus_element(node)
def activate_element(elt)
def scroll_to(elt)
def enter()
def advance_tab()
def zoom_by(increment)
def reset_zoom()
def set_dark_mode(val)
def post_message(message, target_window_id)
class Chrome:
def __init__(browser)
def tab_rect(i)
def paint()
def click(x, y)
def keypress(char)
def enter()
def blur()
def focus_addressbar()
class CommitData:
def __init__(...)
class Browser:
def __init__()
def schedule_animation_frame()
def commit(tab, data)
def render()
def composite_raster_and_draw()
def composite()
def get_latest(effect)
def paint_draw_list()
def raster_tab()
def raster_chrome()
def update_accessibility()
def draw()
def speak_node(node, text)
def speak_document()
def set_needs_accessibility()
def set_needs_animation_frame(tab)
def set_needs_raster_and_draw()
def set_needs_raster()
def set_needs_composite()
def set_needs_draw()
def clear_data()
def new_tab(url)
def new_tab_internal(url)
def set_active_tab(tab)
def schedule_load(url, body)
def clamp_scroll(scroll)
def handle_down()
def handle_click(e)
def handle_key(char)
def handle_enter()
def handle_tab()
def handle_hover(event)
def handle_quit()
def toggle_dark_mode()
def increment_zoom(increment)
def reset_zoom()
def focus_content()
def focus_addressbar()
def go_back()
def cycle_tabs()
def toggle_accessibility()
def mainloop(browser)
16-1 Emptying an element. Implement the replaceChildren
DOM method when called with no arguments. This method should delete
all the children of a given element. Make sure to handle invalidation
properly.
16-2 Protecting layout phases. Replace the
needs_style and needs_layout dirty flags by
making the document field on Frames a
ProtectedField. Make sure animations still work correctly:
animations of opacity or transform shouldn’t
trigger layout, while animations of other properties should.
16-3 Transferring children. Implement the replaceChildren
DOM method when called with multiple arguments. Here the arguments
are elements from elsewhere in the document,Unless you’ve implemented
Exercises 9-2 and 9-3, in which case they can also be “detached”
elements. which are then removed from their current parent
and then attached to this one. Make sure to handle invalidation
properly.
16-4 Descendant bits for style. Add descendant dirty flags
for style information, so that the style phase
doesn’t need to traverse nodes whose styles are unchanged.
16-5 Resizing the browser. Perhaps, back in Exericse 2-3,
you implemented support for resizing the browser. (And, most likely, you
dropped support for it when we switched to SDL.) Reimplement support for
resizing your browser; you’ll need to pass the
SDL_WINDOW_RESIZABLE flag to SDL_CreateWindow
and listen for SDL_WINDOWEVENT_RESIZED events. Make sure
invalidation works: resizing the window should resize the page. How much
does invalidation help make resizing fast? Test both vertical and
horizontal resizing.
16-6 Matching children. Add support for the
appendChild method if you haven’t already in Exercise
9-2. What’s interesting about appendChild is that, while it
does change a layout object’s children field, it
only does so by adding new children to the end. In this case, you can
keep all of the existing layout object children. Apply this
optimization, at least in the case of block-mode
BlockLayouts.
16-7 Invalidating previous. Add support for the
insertBefore method if you if you haven’t already in
Exercise 9-2. Like with appendChild, we want to skip
rebuilding layout objects if we can. However, this method can also
change the previous field of layout objects; protect that
field on all block-mode BlockLayouts and then avoid
rebuilding as much of the layout tree as possible.
16-8 :hover pseudo-class. There is a
:hover pseudo-class that identifies elements the mouse is
hovering
over. Implement it by sending mouse hover events to the active
Tab and hit testing to find out which element is being
hovered over. Try to avoid forcing
a layout in this hit test; one way to do that is to store a
pending_hover on the Tab and run the hit test
after layout during render, and then perform
another render to invalidate the hovered element’s style.
16-9 Optimizing away ProtectedField. As
mentioned in the last section of this chapter, creating all these
ProtectedField objects is way too expensive for a real
browser. See if you can find a way to avoid creating the objects
entirely. Depending on the language you’re using to implement your
browser, you might have compile-time macros available to help; in
Python, this might require refactoring to change the API shape of
ProtectedField to be functional rather than
object-oriented.
16-10 Optimizing paint. Even after making layout fast for text input, paint is still painfully slow. Fix that by storing the display list between frames, adding dirty bits for whether paint is needed for each layout object, and mutating the display list rather than recreating it every time.
Did you find this chapter useful?