
In the previous chapter we gave each
pre element a gray background. It looks OK, and it
is good to have defaults, but sites want a say in how they
look. Websites do that with Cascading Style Sheets (CSS), which
allow web authors (and, as we’ll see, browser developers) to define how
a web page ought to look.
One way a web page can change its appearance is with the
style attribute. For example, this changes an element’s
background color:
<div style="background-color:lightblue">Blue background</div>And it renders like this:
More generally, a style attribute contains
property–value pairs separated by semicolons. The browser looks at those
CSS property–value pairs to determine how an element looks, for example
to determine its background color.
To add this to our browser, we’ll need to start by parsing these
property–value pairs. I’ll use recursive parsing functions,
which are a good way to build a complex parser step by step. The idea is
that each parsing function advances through the text being parsed and
returns the data it parsed. We’ll have different functions for different
types of data, and organize them in a CSSParser class that
stores the text being parsed and the parser’s current position in
it:
class CSSParser:
def __init__(self, s):
self.s = s
self.i = 0Let’s start small and build up. A parsing function for whitespace
increments the index i past every whitespace character:
def whitespace(self):
while self.i < len(self.s) and self.s[self.i].isspace():
self.i += 1Whitespace is meaningless, so there’s no parsed data to return. But when we parse property names, we’ll want to return them:
def word(self):
start = self.i
while self.i < len(self.s):
if self.s[self.i].isalnum() or self.s[self.i] in "#-.%":
self.i += 1
else:
break
if not (self.i > start):
raise Exception("Parsing error")
return self.s[start:self.i]This function increments i through any word
characters,I’ve chosen
the set of word characters here to cover property names (which use
letters and the dash), numbers (which use the minus sign, numbers,
periods), units (the percent sign), and colors (which use the hash
sign). Real CSS values have a more complex syntax but this is enough for
our browser. much like whitespace. But to
return the parsed data, it stores where it started and extracts the
substring it moved through.
Parsing functions can fail. The word function we just
wrote raises an exception if i hasn’t advanced through at
least one character—otherwise it didn’t point at a word to begin
with.You can add error
text to the exception-raising code, too; I recommend doing that to help
you debug problems. Likewise, to check for a literal colon
(or some other punctuation character) you’d do this:
def literal(self, literal):
if not (self.i < len(self.s) and self.s[self.i] == literal):
raise Exception("Parsing error")
self.i += 1The great thing about parsing functions is that they can build on one
another. For example, property–value pairs are a property, a colon, and
a value,In reality,
properties and values have different syntaxes, so using
word for both isn’t quite right, but for our browser’s
limited CSS implementation this simplification will do.
with whitespace in between:
def pair(self):
prop = self.word()
self.whitespace()
self.literal(":")
self.whitespace()
val = self.word()
return prop.casefold(), valWe can parse sequences by calling parsing functions in a loop. For
example, style attributes are a sequence of property–value
pairs:
def body(self):
pairs = {}
while self.i < len(self.s):
prop, val = self.pair()
pairs[prop] = val
self.whitespace()
self.literal(";")
self.whitespace()
return pairsNow, in a browser, we always have to think about handling errors. Sometimes a web page author makes a mistake; sometimes our browser doesn’t support a feature some other browser does. So we should skip property–value pairs that don’t parse, but keep the ones that do.
We can skip things with this little function; it stops at any one of
a set of characters and returns that character (or None if
it was stopped by the end of the file):
def ignore_until(self, chars):
while self.i < len(self.s):
if self.s[self.i] in chars:
return self.s[self.i]
else:
self.i += 1
return NoneWhen we fail to parse a property–value pair, we skip either to the next semicolon or to the end of the string:
def body(self):
# ...
while self.i < len(self.s):
try:
# ...
except Exception:
why = self.ignore_until([";"])
if why == ";":
self.literal(";")
self.whitespace()
else:
break
# ...Skipping parse errors is a double-edged sword. It hides error
messages, making it harder for authors to debug their style sheets; it
also makes it harder to debug your parser.I suggest removing the
try block when debugging. So in most
programming situations this “catch-all” error handling is a code
smell.
But “catch-all” error handling has an unusual benefit on the web. The
web is an ecosystem of many browsers,And an ecosystem of many browser versions, some of which
haven’t been written yet—but need to be supported as best we
can. which (for example) support different kinds of
property values.Our
browser does not support parentheses in property values, for example,
which real browsers use for things like the calc and
url functions. CSS that parses in one browser
might not parse in another. With silent parse errors, browsers just
ignore stuff they don’t understand, and web pages mostly work in all of
them. The principle (variously called “Postel’s Law”,After a line in the
specification of TCP, written by Jon Postel. the “Digital
Principle”,After a
similar idea in circuit design, where transistors must be non-linear to
reduce analog noise. or the “Robustness Principle”) is:
produce maximally conformant output but accept even minimally conformant
input.
This parsing method is formally called recursive descent parsing for an LL(1) language. Parsers that use this method can be really, really fast, at least if you put a lot of work into it. In a browser, faster parsing means pages load faster.
style AttributeNow that the style attribute is parsed, we can use that
parsed information in the rest of the browser. Let’s do that inside a
style function, which saves the parsed style
attribute in the node’s style field:
def style(node):
node.style = {}
if isinstance(node, Element) and "style" in node.attributes:
pairs = CSSParser(node.attributes["style"]).body()
for property, value in pairs.items():
node.style[property] = valueThe method can recurse through the HTML tree to make sure each element gets a style:
def style(node):
# ...
for child in node.children:
style(child)Call style in the browser’s load method,
after parsing the HTML but before doing layout. With the
style information stored on each element, the browser can
consult it for styling information during paint:
class BlockLayout:
def paint(self):
# ...
bgcolor = self.node.style.get("background-color",
"transparent")
if bgcolor != "transparent":
x2, y2 = self.x + self.width, self.y + self.height
rect = DrawRect(self.x, self.y, x2, y2, bgcolor)
cmds.append(rect)
# ...I’ve removed the default gray background from pre
elements for now, but we’ll put it back soon.
Open the web version of this chapter up in your browser to test your code: the code block at the start of the chapter should now have a light blue background.
So this is one way web pages can change their appearance. And in the
early days of the web,I’m talking Netscape 3. The late 1990s.
something like this was the only way. But honestly, it’s a
pain—you need to set a style attribute on each element, and
if you redesign the page, that’s a lot of attributes to edit. CSS was
invented to improve on this state of affairs:
To achieve these goals, CSS extends the style attribute
with two related ideas: selectors and cascading.
Selectors describe which HTML elements a list of property–value pairs
apply to.CSS rules can
also be guarded by “media queries”, which say that a rule should apply
only in certain browsing environments (like only on mobile or only in
landscape mode). Media queries are super-important for building sites
that work across many devices, like reading this book on a phone. We’ll
meet them in Chapter 14.
The combination of the two is called a rule, as shown in Figure
1.
Let’s add support for CSS to our browser. We’ll need to parse CSS
files into selectors and property–value pairs, figure out which elements
on the page match each selector, and copy those property values to the
elements’ style fields.
Actually, before CSS, you’d style pages with custom
presentational tags like font
and center
(not to mention the <b> and <i>
tags that we’ve already seen). This was easy to implement but made it
hard to keep pages consistent. There were also properties on
<body> like text
and vlink that could consistently set text colors,
mainly for links.
Selectors come in lots of types, but in our browser we’ll support
two: tag selectors (p selects all <p>
elements, ul selects all <ul> elements)
and descendant selectors (article div selects all
div elements with an article ancestor).The descendant selector
associates to the left; in other words, a b c means a
<c> that descends from a <b> that
descends from an <a>, which maybe you’d write
(a b) c if CSS had parentheses.
We’ll have a class for each type of selector to store the selector’s contents, like the tag name for a tag selector:
class TagSelector:
def __init__(self, tag):
self.tag = tagEach selector class will also test whether the selector matches an element:
class TagSelector:
def matches(self, node):
return isinstance(node, Element) and self.tag == node.tagA descendant selector works similarly. It has two parts, which are both themselves selectors:
class DescendantSelector:
def __init__(self, ancestor, descendant):
self.ancestor = ancestor
self.descendant = descendantThen the matches method is recursive:
class DescendantSelector:
def matches(self, node):
if not self.descendant.matches(node): return False
while node.parent:
if self.ancestor.matches(node.parent): return True
node = node.parent
return FalseNow, to create these selector objects, we need a parser. In this
case, that’s just another parsing function:Once again, using
word here for tag names is actually not quite right, but
it’s close enough. One side effect of using word is that a
class name selector (like .main) or an identifier selector
(like #signup) is mis-parsed as a tag name selector. But,
luckily, that won’t cause any harm since there aren’t any elements with
those tags.
class CSSParser:
def selector(self):
out = TagSelector(self.word().casefold())
self.whitespace()
while self.i < len(self.s) and self.s[self.i] != "{":
tag = self.word()
descendant = TagSelector(tag.casefold())
out = DescendantSelector(out, descendant)
self.whitespace()
return outA CSS file is just a sequence of selectors and blocks:
def parse(self):
rules = []
while self.i < len(self.s):
self.whitespace()
selector = self.selector()
self.literal("{")
self.whitespace()
body = self.body()
self.literal("}")
rules.append((selector, body))
return rulesOnce again, let’s pause to think about error handling. First, when we
call body while parsing CSS, we need it to stop when it
reaches a closing brace:
def body(self):
# ...
while self.i < len(self.s) and self.s[self.i] != "}":
try:
# ...
except Exception:
why = self.ignore_until([";", "}"])
if why == ";":
self.literal(";")
self.whitespace()
else:
break
# ...Second, there might also be a parse error while parsing a selector. In that case, we want to skip the whole rule:
def parse(self):
# ...
while self.i < len(self.s):
try:
# ...
except Exception:
why = self.ignore_until(["}"])
if why == "}":
self.literal("}")
self.whitespace()
else:
break
# ...Error handling is hard to get right, so make sure to test your parser, just like the HTML parser in Chapter 4. Here are some errors you might run into:
If the output is missing some rules or properties, it’s probably
a bug being hidden by error handling. Remove some try
blocks and see if the error in question can be fixed.
If you’re seeing extra rules or properties that are mangled
versions of the correct ones, you probably forgot to update
i somewhere.
If you’re seeing an infinite loop, check whether the
error-handling code always increases i. Each parsing
function (except whitespace) should always increment
i.
You can also add a print statement to the start and
endIf you print an open
parenthesis at the start of the function and a close parenthesis at the
end, you can use your editor’s “jump to other parenthesis” feature to
skip through output quickly. of each parsing function with
the name of the parsing function,If you also add the right number of spaces to each line
it’ll be a lot easier to read. Don’t neglect debugging niceties like
this! the index i,It can be especially helpful
to print, say, the 20 characters around index i from the
string. and the parsed data. It’s a lot of output, but
it’s a sure-fire way to find really complicated bugs.
A parser receives arbitrary bytes as input, so parser bugs are usually easy for bad actors to exploit. Parser correctness is thus crucial to browser security, as many parser bugs have demonstrated. Nowadays browser developers use fuzzing to try to find and fix such bugs.
With the parser debugged, the next step is applying the parsed style sheet to the web page. Since each CSS rule can style many elements on the page, this will require looping over all elements and all rules. When a rule applies, its property–value pairs are copied to the element’s style information:
def style(node, rules):
# ...
for selector, body in rules:
if not selector.matches(node): continue
for property, value in body.items():
node.style[property] = value
# ...Make sure to put this loop before the one that parses the
style attribute: the style attribute should
override style sheet values.
To try this out, we’ll need a style sheet. Every browser ships with a browser style sheet,Technically called a “user agent” style sheet. User agent, like the Memex. which defines its default styling for the various HTML elements. For our browser, it might look like this:
pre { background-color: gray; }Let’s store that in a new file, browser.css, and have
our browser read it when it starts:
DEFAULT_STYLE_SHEET = CSSParser(open("browser.css").read()).parse()Now, when the browser loads a web page, it can apply that default style sheet to set up its default styling for each element:
def load(self, url):
# ...
rules = DEFAULT_STYLE_SHEET.copy()
style(self.nodes, rules)
# ...The browser style sheet is the default for the whole web. But each
web site can also use CSS to set a consistent style for the whole site
by referencing CSS files using link elements:
<link rel="stylesheet" href="/main.css">The mandatory rel attribute identifies this link as a
style sheetFor browsers,
stylesheet is the most important kind
of link, but there’s also preload for loading assets
that a page will use later and icon for identifying
favicons. Search engines also use these links; for example,
rel=canonical names the “true name” of a page and search
engines use it to track pages that appear at multiple
URLs. and the href attribute has the style
sheet URL. We need to find all these links, download their style sheets,
and apply them, as in Figure 2.
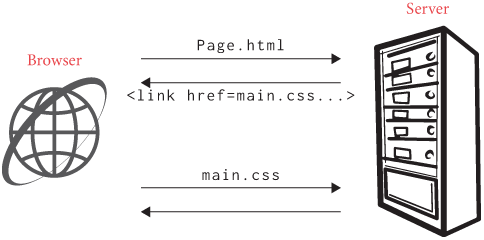
Since we’ll be doing similar tasks in the next few chapters, let’s generalize a bit and write a recursive function that turns a tree into a list of nodes:
def tree_to_list(tree, list):
list.append(tree)
for child in tree.children:
tree_to_list(child, list)
return listI’ve written this helper to work on both HTML and layout trees, for
later. We can use tree_to_list with a Python list
comprehension to grab the URL of each linked style sheet:It’s kind of crazy, honestly,
that Python lets you write things like this—crazy, but very
convenient!
def load(self, url):
# ...
links = [node.attributes["href"]
for node in tree_to_list(self.nodes, [])
if isinstance(node, Element)
and node.tag == "link"
and node.attributes.get("rel") == "stylesheet"
and "href" in node.attributes]
# ...Now, these style sheet URLs are usually not full URLs; they are something called relative URLs, which can be:There are other flavors, including query-relative, that I’m skipping.
//” followed by
a full URL, which should use the existing scheme.To download the style sheets, we’ll need to convert each relative URL into a full URL:
class URL:
def resolve(self, url):
if "://" in url: return URL(url)
if not url.startswith("/"):
dir, _ = self.path.rsplit("/", 1)
url = dir + "/" + url
if url.startswith("//"):
return URL(self.scheme + ":" + url)
else:
return URL(self.scheme + "://" + self.host + \
":" + str(self.port) + url)Also, because of the early web architecture, browsers are responsible
for resolving parent directories (..) in relative URLs:
class URL:
def resolve(self, url):
if not url.startswith("/"):
dir, _ = self.path.rsplit("/", 1)
while url.startswith("../"):
_, url = url.split("/", 1)
if "/" in dir:
dir, _ = dir.rsplit("/", 1)
url = dir + "/" + urlNow the browser can request each linked style sheet and add its rules
to the rules list:
def load(self, url):
# ...
for link in links:
style_url = url.resolve(link)
try:
body = style_url.request()
except:
continue
rules.extend(CSSParser(body).parse())The try/except ignores style sheets that
fail to download, but it can also hide bugs in your code, so if
something’s not right try removing it temporarily.
Each browser engine has its own browser style sheet (Chromium, WebKit, Gecko). Reset style sheets are often used to overcome any differences. This works because web page style sheets take precedence over the browser style sheet, just like in our browser, though real browsers fiddle with priorities to make that happen.Our browser style sheet only has tag selectors in it, so just putting them first works well enough. But if the browser style sheet had any descendant selectors, we’d encounter bugs.
A web page can now have any number of style sheets applied to it. And since two rules can apply to the same element, rule order matters: it determines which rules take priority, and when one rule overrides another.
In CSS, the correct order is called cascade order, and it is based on the rule’s selector, with file order as a tie breaker. This system allows more specific rules to override more general ones, so that you can have a browser style sheet, a site-wide style sheet, and maybe a special style sheet for a specific web page, all co-existing.
Since our browser only has tag selectors, cascade order just counts them:
class TagSelector:
def __init__(self, tag):
# ...
self.priority = 1
class DescendantSelector:
def __init__(self, ancestor, descendant):
# ...
self.priority = ancestor.priority + descendant.priorityThen cascade order for rules is just those priorities:
def cascade_priority(rule):
selector, body = rule
return selector.priorityNow when we call style, we need to sort the rules, like
this:
def load(self, url):
# ...
style(self.nodes, sorted(rules, key=cascade_priority))
# ...Note that before sorting rules, it is in file order.
Python’s sorted function keeps the relative order of things
with equal priority, so file order acts as a tie breaker, as it
should.
That’s it: we’ve added CSS to our web browser! I mean—for background
colors. But there’s more to web design than that. For example, if you’re
changing background colors you might want to change foreground colors as
well—the CSS color property. But there’s a catch:
color affects text, and there’s no way to select a text
node. How can that work?
Web pages can also supply alternative style sheets, and some browsers provide (obscure) methods to switch from the default to an alternate style sheet. The CSS standard also allows for user styles that set custom style sheets for websites, with a priority between browser and website-provided style sheets.
The way text styles work in CSS is called inheritance. Inheritance means that if some node doesn’t have a value for a certain property, it uses its parent’s value instead. That includes text nodes. Some properties are inherited and some aren’t; it depends on the property. Background color isn’t inherited, but text color and other font properties are.
Let’s implement inheritance for four font properties:
font-size, font-style (for
italic), font-weight (for bold),
and color:
INHERITED_PROPERTIES = {
"font-size": "16px",
"font-style": "normal",
"font-weight": "normal",
"color": "black",
}The values in this dictionary are each property’s defaults. We’ll
then add the actual inheritance code to the style function.
It has to come before the other loops, since explicit rules
should override inheritance:
def style(node, rules):
# ...
for property, default_value in INHERITED_PROPERTIES.items():
if node.parent:
node.style[property] = node.parent.style[property]
else:
node.style[property] = default_value
# ...Inheriting font size comes with a twist. Web pages can use
percentages as font sizes: h1 { font-size: 150% } makes
headings 50% bigger than the surrounding text. But what if you had, say,
a code element inside an h1 tag—would that
inherit the 150% value for font-size? Surely
it shouldn’t be another 50% bigger than the rest of the heading
text?
In fact, browsers resolve font size percentages to absolute pixel
units before those values are inherited; it’s called a “computed
style”.The full CSS
standard is a bit more confusing: there are specified,
computed, used, and actual values, and they affect lots of CSS
properties besides font-size. But we’re not implementing
those other properties in this book.
def style(node, rules):
# ...
if node.style["font-size"].endswith("%"):
# ...
for child in node.children:
style(child, rules)Resolving percentage sizes has just one tricky edge case: percentage
sizes for the root html element. In that case the
percentage is relative to the default font size:This code has to parse and
unparse font sizes because our style field stores strings;
in a real browser the computed style is stored parsed so this doesn’t
have to happen.
def style(node, rules):
# ...
if node.style["font-size"].endswith("%"):
if node.parent:
parent_font_size = node.parent.style["font-size"]
else:
parent_font_size = INHERITED_PROPERTIES["font-size"]
node_pct = float(node.style["font-size"][:-1]) / 100
parent_px = float(parent_font_size[:-2])
node.style["font-size"] = str(node_pct * parent_px) + "px"Note that this happens after all of the different sources of style
values are handled (so we are working with the final
font-size value) but before we recurse (so any children can
assume that their parent’s font-size has been resolved to a
pixel value).
Styling a page can be slow, so real browsers apply tricks like bloom filters for descendant selectors, indices for simple selectors, and various forms of sharing and parallelism. Some types of sharing are also important to reduce memory usage—computed style sheets can be huge!
So now with all these font properties implemented, let’s change layout to use them! That will let us move our default text styles to the browser style sheet:
a { color: blue; }
i { font-style: italic; }
b { font-weight: bold; }
small { font-size: 90%; }
big { font-size: 110%; }The browser looks up font information in BlockLayout’s
word method; we’ll need to change it to use the node’s
style field, and for that, we’ll need to pass in the node
itself:
class BlockLayout:
def recurse(self, node):
if isinstance(node, Text):
for word in node.text.split():
self.word(node, word)
else:
# ...
def word(self, node, word):
weight = node.style["font-weight"]
style = node.style["font-style"]
if style == "normal": style = "roman"
size = int(float(node.style["font-size"][:-2]) * .75)
font = get_font(size, weight, style)
# ...Note that for font-style we need to translate CSS
“normal” to Tk “roman” and for font-size we need to convert
CSS pixels to Tk points.
Text color requires a bit more plumbing. First, we have to read the
color and store it in the current line:
def word(self, node, word):
color = node.style["color"]
# ...
self.line.append((self.cursor_x, word, font, color))
# ...The flush method then copies it from line
to display_list:
def flush(self):
# ...
metrics = [font.metrics() for x, word, font, color in self.line]
# ...
for rel_x, word, font, color in self.line:
# ...
self.display_list.append((x, y, word, font, color))
# ...That display_list is converted to drawing commands in
paint:
def paint(self):
# ...
if self.layout_mode() == "inline":
for x, y, word, font, color in self.display_list:
cmds.append(DrawText(x, y, word, font, color))DrawText now needs a color argument, and
needs to pass it to create_text’s fill
parameter:
class DrawText:
def __init__(self, x1, y1, text, font, color):
# ...
self.color = color
def execute(self, scroll, canvas):
canvas.create_text(
# ...
fill=self.color)Phew! That was a lot of coordinated changes, so test everything and
make sure it works. You should now see links on the web version of this
chapter appear in blue—and you might also notice that the rest of
the text has become slightly lighter.The main body text on the web is colored #333,
or roughly 97% black after gamma
correction. Also, now that we’re explicitly setting
the text color, we should explicitly set the background color as
well:My Linux machine
sets the default background color to a light gray, while my macOS laptop
has a “Dark Mode” where the default background color becomes a dark
gray. Setting the background color explicitly avoids the browser looking
strange in these situations.
class Browser:
def __init__(self):
# ...
self.canvas = tkinter.Canvas(
# ...
bg="white",
)
# ...These changes obsolete all the code in BlockLayout that
handles specific tags, like the style, weight,
and size properties and the open_tag and
close_tag methods. Let’s refactor a bit to get rid of
them:
class BlockLayout:
def recurse(self, node):
if isinstance(node, Text):
for word in node.text.split():
self.word(node, word)
else:
if node.tag == "br":
self.flush()
for child in node.children:
self.recurse(child)Styling not only lets web page authors style their own web pages; it also moves browser code to a simple style sheet. And that’s a big improvement: the style sheet is simpler and easier to edit. Sometimes converting code to data like this means maintaining a new format, but browsers get to reuse a format, CSS, they need to support anyway.
But of course styling also has the nice benefit of nicely rendering this book’s homepage (Figure 3). Notice how the background is no longer gray, and the links have colors.

Usually a point is 1/72 of an inch while pixel size depends on the screen, but CSS instead defines an inch as 96 pixels, because that was once a common screen resolution. And these CSS pixels need not be physical pixels! Seem weird? This complexity is the result of changes in browsers (zooming) and hardware (high-DPIDots per inch. screens) plus the need to be compatible with older web pages meant for the time when all screens had 96 pixels per inch.
This chapter implemented a rudimentary but complete styling engine, including downloading, parsing, matching, sorting, and applying CSS files. That means we:
style attributes and
linked CSS files;BlockLayout to move the font properties to
CSS;Our styling engine is also relatively easy to extend with properties and selectors.
The complete set of functions, classes, and methods in our browser should now look something like this:
class URL:
def __init__(url)
def request()
def resolve(url)
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
def tree_to_list(tree, list)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
class CSSParser:
def __init__(s)
def whitespace()
def literal(literal)
def word()
def ignore_until(chars)
def pair()
def selector()
def body()
def parse()
class TagSelector:
def __init__(tag)
def matches(node)
class DescendantSelector:
def __init__(ancestor, descendant)
def matches(node)
FONTS
def get_font(size, weight, style)
DEFAULT_STYLE_SHEET
INHERITED_PROPERTIES
def style(node, rules)
def cascade_priority(rule)
WIDTH, HEIGHT
HSTEP, VSTEP
BLOCK_ELEMENTS
class DocumentLayout:
def __init__(node)
def layout()
def paint()
class BlockLayout:
def __init__(node, parent, previous)
def layout_mode()
def layout()
def recurse(node)
def flush()
def word(node, word)
def paint()
class DrawText:
def __init__(x1, y1, text, font, color)
def execute(scroll, canvas)
class DrawRect:
def __init__(x1, y1, x2, y2, color)
def execute(scroll, canvas)
def paint_tree(layout_object, display_list)
SCROLL_STEP
class Browser:
def __init__()
def draw()
def load(url)
def scrolldown(e)
6-1 Fonts. Implement the font-family property,
an inheritable property that names which font should be used in an
element. Make text inside <code> elements use a nice
monospaced font like Courier. Beware the font cache.
6-2 Width/height. Add support for the width and
height properties to block layout. These can either be a
pixel value, which directly sets the width or height of the layout
object, or the word auto, in which case the existing layout
algorithm is used.
6-3 Class selectors. Any HTML element can have a
class attribute, whose value is a space-separated list of
that element’s classes. A CSS class selector, like .main,
affects all elements with the main class. Implement class
selectors; they should take precedence over tag selectors. If you’ve
implemented them correctly, you should see syntax highlighting for the
code blocks in this book.
6-4 display. Right now, the
layout_mode function relies on a hard-coded list of block
elements. In a real browser, the display property controls
this. Implement display with a default value of
inline, and move the list of block elements to the browser
style sheet.
6-5 Shorthand properties CSS “shorthand properties” set
multiple related CSS properties at the same time; for example,
font: italic bold 100% Times sets the
font-style, font-weight,
font-size, and font-family properties all at
once. Add shorthand properties to your parser. (If you haven’t done
Exercise 6-1, just ignore the font-family.)
6-6 Inline style sheets. The
<link rel=stylesheet> syntax allows importing an
external style sheet (meaning one loaded via its own HTTP request).
There is also a way to provide a style sheet inline, as part of the
HTML, via the <style> tag—everything up to the
following </style> tag is interpreted as a style
sheet.Both inline and
external stylesheet apply in the order of their appearance in the HTML,
though it might be easier to first implement inline style sheets
applying after external ones. Inline style sheets are
useful for creating self-contained example web pages, but more
importantly are a way that websites can load faster by reducing the
number of round-trip network requests to the server. Since style sheets
typically don’t contain left angle brackets, you can implement this
feature without modifying the HTML parser.
6-7 Fast descendant selectors. Right now, matching a
selector like div div div div div can take a long time—it’s
*O(nd)* in the worst case, where n is the length of the
selector and d is the depth of the layout tree. Modify the
descendant-selector matching code to run in *O(n + d)* time. It may help
to have DescendantSelector store a list of base selectors
instead of just two.
6-8 Selector sequences. Sometimes you want to select an
element by tag and class. You do this by concatenating the
selectors without anything in between.Not even whitespace! For example,
span.announce selects elements that match both
span and .announce. Implement a new
SelectorSequence class to represent these and modify the
parser to parse them. Sum priorities.Priorities for SelectorSequences are supposed
to compare the number of ID, class, and tag selectors in lexicographic
order, but summing the priorities of the selectors in the sequence will
work fine as long as no one strings more than ten selectors
together.
6-9 !important. A CSS property–value pair can
be marked “important” using the !important syntax, like
this:
#banner a { color: black !important; }This gives that property–value pair (but not other pairs in the same
block!) a higher priority than any other selector (except for other
!important properties). Parse and implement
!important, giving any property–value pairs marked this way
a priority 10 000 higher than normal property–value pairs.
6-10 :has selectors. The :has
selector is the inverse of a descendant selector—it styles an
ancestor according to the presence of a descendant. Implement
:has selectors. Analyze the asymptotic speed of your
implementation. There is a clever implementation that is *O(1)*
amortized per element—can you find it?In fact, browsers have to do something even
more complex to implement :has
efficiently.
Did you find this chapter useful?