So far, layout has been a linear process that handles open tags and close tags independently. But web pages are trees, and look like them: borders and backgrounds visually nest inside one another. To support that, this chapter switches to tree-based layout, where the tree of elements is transformed into a tree of layout objects before drawing. In the process, we’ll make web pages more colorful with backgrounds.
Right now, our browser lays out an element’s open and close tags
separately. Both tags modify global state, like the
cursor_x and cursor_y variables, but they
aren’t otherwise connected, and information about the element as a
whole, like its width and height, is never computed. That makes it
pretty hard to draw a background behind an element, let alone more
complicated visual effects. So web browsers structure layout
differently.
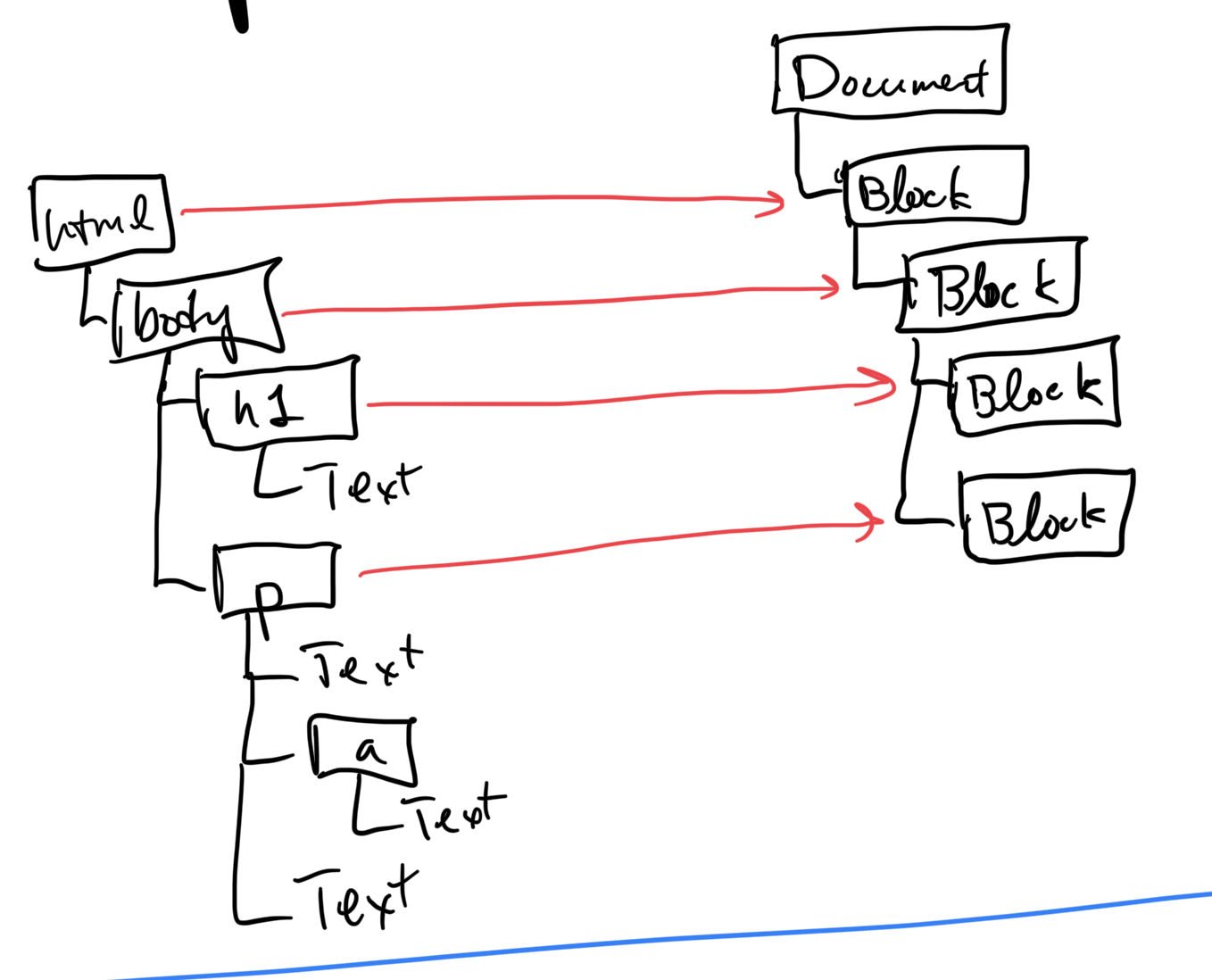
In a browser, layout is about producing a layout tree, whose
nodes are layout objects, each associated with an HTML
elementElements like
<script> don’t generate layout objects, and some
elements generate multiple layout objects (<li>
elements have an extra one for the bullet point!), but mostly it’s one
layout object each. and each with a size and a position.
The browser walks the HTML tree to produce the layout tree, then
computes the size and position for each layout object, and finally draws
each layout object to the screen.
Let’s start by looking at how the existing Layout class
is used:
class Browser:
def load(self, url):
# ...
self.display_list = Layout(self.nodes).display_list
#...Here, a Layout object is created briefly and then thrown
away. Let’s instead make it the beginning of our layout tree by storing
it in a Browser field:
class Browser:
def load(self, url):
# ...
self.document = Layout(self.nodes)
self.document.layout()
#...Note that I’ve renamed the Layout constructor to a
layout method, so that constructing a layout object and
actually laying it out can be different steps. The constructor now just
stores the node it was passed:
class Layout:
def __init__(self, node):
self.node = nodeSo far, we still don’t have a tree—we just have a single
Layout object. To make it into a tree, we’ll need to add
child and parent pointers. I’m also going to add a pointer to the
previous sibling, because that’ll be useful for computing sizes and
positions later:
class Layout:
def __init__(self, node, parent, previous):
self.node = node
self.parent = parent
self.previous = previous
self.children = []That said, requiring a parent and previous
element now makes it tricky to construct a Layout object in
Browser, since the root of the layout tree obviously can’t
have a parent. To rectify that, let me add a second kind of layout
object to serve as the root of the layout tree.I don’t want to just pass
None for the parent, because the root layout object also
computes its size and position differently, as we’ll see later in this
chapter. I think of that root as the document itself, so
let’s call it DocumentLayout:
class DocumentLayout:
def __init__(self, node):
self.node = node
self.parent = None
self.children = []
def layout(self):
child = Layout(self.node, self, None)
self.children.append(child)
child.layout()Note an interesting thing about this new layout method:
its role is to create the child layout objects and then
recursively call their layout methods. This is a
common pattern for constructing trees; we’ll be seeing it a lot
throughout this book.
Now when we construct a DocumentLayout object inside
load, we’ll be building a tree; a very short tree, more of
a stump (just the “document” and the HTML element below it), but a tree
nonetheless!
By the way, since we now have DocumentLayout, let’s
rename Layout so it’s less ambiguous. I like
BlockLayout as a name, because we ultimately want
Layout to represent a block of text, like a paragraph or a
heading:
class BlockLayout:
# ...Make sure to rename the Layout constructor call in
DocumentLayout as well. As always, test your browser and
make sure that after all of these refactors, everything still works.
The layout tree isn’t accessible to web developers, so it hasn’t been standardized, and its structure differs between browsers. Even the names don’t match! Chrome calls it a layout tree, Safari a render tree, and Firefox a frame tree.
The layout tree has a 1:1 correspondence with the HTML tree.
The layout method for some layout modes calls
layout recursively. Where does this recursion bottom
out?
InlineLayout object.DocumentLayout object.What type of object is at the root of the layout tree? The intermediate nodes? The leaves?
So far, we’ve focused on text layout—and text is laid out horizontally in lines.In European languages, at least! But web pages are really constructed out of larger blocks, like headings, paragraphs, and menus, that stack vertically one after another. We need to add support for this kind of layout to our browser, and the way we’re going to do that involves expanding on the layout tree we’ve already built.
The core idea is that we’ll have a whole tree of
BlockLayout objects (with a DocumentLayout at
the root). Some will represent leaf blocks that contain text, and
they’ll lay out their contents the way we’ve already implemented. But
there will also be new, intermediate BlockLayouts with
BlockLayout children, and they will stack their children
vertically.
To create these intermediate BlockLayout children, we
can use a loop like this:
class BlockLayout:
def layout_intermediate(self):
previous = None
for child in self.node.children:
next = BlockLayout(child, self, previous)
self.children.append(next)
previous = nextI’ve called this method layout_intermediate, but only so
you can add it to the code right away and then compare it with the
existing recurse method.
This code is tricky, so read it carefully. It involves two trees: the
HTML tree, which node and child point to; and
the layout tree, which self, previous, and
next point to. The two trees have similar structure, so
it’s easy to get confused. But remember that this code constructs the
layout tree from the HTML tree, so it reads from
node.children (in the HTML tree) and writes to
self.children (in the layout tree).
So we have two ways to lay out an element: either calling
recurse and flush, or this
layout_intermediate function. To determine which one a
layout object should use, we’ll need to know what kind of content its
HTML node contains: text and text-related tags like
<b>, or blocks like <p> and
<h1>. That function looks something like this:
class BlockLayout:
def layout_mode(self):
if isinstance(self.node, Text):
return "inline"
elif any([isinstance(child, Element) and \
child.tag in BLOCK_ELEMENTS
for child in self.node.children]):
return "block"
elif self.node.children:
return "inline"
else:
return "block"Here, the list of BLOCK_ELEMENTS is basically what you
expect, a list of all the tags that describe blocks and containers:Taken from the HTML living
standard.
BLOCK_ELEMENTS = [
"html", "body", "article", "section", "nav", "aside",
"h1", "h2", "h3", "h4", "h5", "h6", "hgroup", "header",
"footer", "address", "p", "hr", "pre", "blockquote",
"ol", "ul", "menu", "li", "dl", "dt", "dd", "figure",
"figcaption", "main", "div", "table", "form", "fieldset",
"legend", "details", "summary"
]Our layout_mode method has to handle one tricky case,
where a node contains both block children like a <p>
element and also text children like a text node or a
<b> element. It’s probably best to think of this as a
kind of error on the part of the web developer. And just like with
implicit tags in Chapter 4, we need a repair
mechanism to make sense of the situation; I’ve chosen to use block mode
in this case.In real
browsers, that repair mechanism is called “anonymous
block boxes” and is more complex than what’s described
here.
So now BlockLayout can determine what kind of layout to
do based on the layout_mode of its HTML node:
class BlockLayout:
def layout(self):
mode = self.layout_mode()
if mode == "block":
previous = None
for child in self.node.children:
next = BlockLayout(child, self, previous)
self.children.append(next)
previous = next
else:
self.cursor_x = 0
self.cursor_y = 0
self.weight = "normal"
self.style = "roman"
self.size = 12
self.line = []
self.recurse(self.node)
self.flush()Finally, since BlockLayouts can now have children, the
layout method next needs to recursively call
layout so those children can construct their children, and
so on recursively:
class BlockLayout:
def layout(self):
# ...
for child in self.children:
child.layout()Our browser is now constructing a whole tree of
BlockLayout objects; you can use print_tree to
see this tree in the Browser’s load method.
You’ll see that large web pages like this chapter produce large and
complex layout trees! (An example is shown in Figure 1.) Now we need
each of these BlockLayout objects to have a size and
position somewhere on the page.
In CSS, the layout mode is set by the display
property. The oldest CSS layout modes, like inline and
block, are set on the children instead of the parent, which
leads to hiccups like anonymous
block boxes. Newer properties like inline-block,
flex, and grid are set on the parent, which
avoids this kind of error.
In the previous chapter, the
Layout object was responsible for the whole web page, so it
just laid out its content starting at the top of the page. Now that we
have multiple BlockLayout objects each containing a
different paragraph of text, we’re going to need to do things a little
differently, computing a size and position for each layout object
independently.
Let’s add x, y, width, and
height fields for each layout object type:
class BlockLayout:
def __init__(self, node, parent, previous):
# ...
self.x = None
self.y = None
self.width = None
self.height = NoneDo the same for DocumentLayout. Now we need to update
the layout method to use these fields.
Let’s start with cursor_x and cursor_y.
Instead of having them denote absolute positions on the page, let’s make
them relative to the BlockLayout’s x and
y. So they now need to start from 0 instead of
HSTEP and VSTEP, in both layout
and flush:
class BlockLayout:
def layout(self):
else:
self.cursor_x = 0
self.cursor_y = 0
def flush(self):
# ...
self.cursor_x = 0
# ...Since these fields are now relative, we’ll need to add the block’s
x and y position in flush when
computing the display list:
class BlockLayout:
def flush(self):
# ...
for rel_x, word, font in self.line:
x = self.x + rel_x
y = self.y + baseline - font.metrics("ascent")
self.display_list.append((x, y, word, font))
# ...Similarly, to wrap lines, we can’t compare cursor_x to
WIDTH, because cursor_x is a relative position
while WIDTH is an absolute position; instead, we’ll wrap
lines when cursor_x reaches the block’s
width:
class BlockLayout:
def word(self, word):
# ...
if self.cursor_x + w > self.width:
# ...
# ...So now that leaves us with the problem of computing these
x, y, and width fields. Let’s
recall that BlockLayouts represent blocks of text like
paragraphs or headings, and are stacked vertically one atop another.
That means each one starts at its parent’s left edge and goes all the
way across its parent:In
the next chapter, we’ll add support for
author-defined styles, which in real browsers modify these layout rules
by setting custom widths or changing how x and y
positions are computed.
class BlockLayout:
def layout(self):
self.x = self.parent.x
self.width = self.parent.width
# ...A layout object’s vertical position depends on whether there’s a previous sibling. If there is one, the layout object starts right after it; otherwise, it starts at its parent’s top edge:
class BlockLayout:
def layout(self):
if self.previous:
self.y = self.previous.y + self.previous.height
else:
self.y = self.parent.y
# ...Finally, height is a little tricky. A BlockLayout that
contains other blocks should be tall enough to contain all of its
children, so its height should be the sum of its children’s heights:
class BlockLayout:
def layout(self):
# ...
if mode == "block":
self.height = sum([
child.height for child in self.children])However, a BlockLayout that contains text doesn’t have
children; instead, it needs to be tall enough to contain all its text,
which we can conveniently read off from cursor_y:Since the height is just equal
to cursor_y, why not rename cursor_y to
height instead? You could, it would work fine, but I would
rather not. As you can see from, say, the y computation,
the height field is a public field, read by other layout
objects to compute their positions. As such, I’d rather make sure it
always has the right value, whereas cursor_y
changes as we lay out a paragraph of text and therefore sometimes has
the “wrong” value. Keeping these two fields separate avoids a whole
class of nasty bugs where the height field is read “too
soon” and therefore gets the wrong value.
class BlockLayout:
def layout(self):
# ...
else:
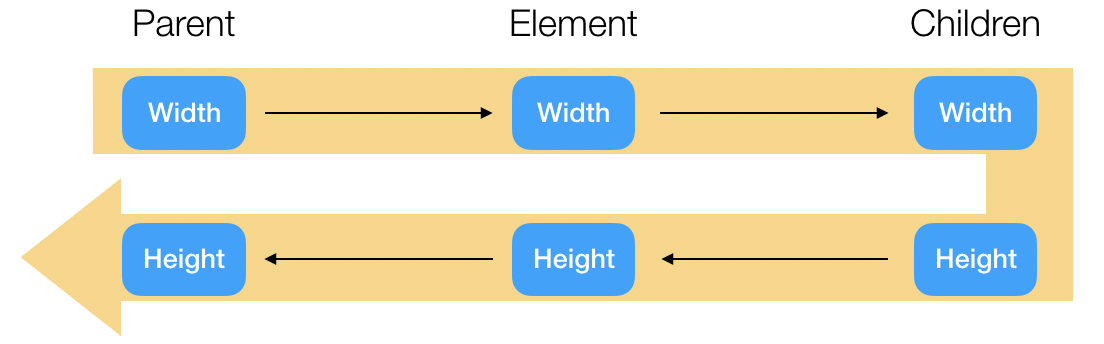
self.height = self.cursor_yThese rules seem simple enough, but there’s a subtlety here I have to
explain. Consider the x position. To compute a block’s
x position, the x position of its parent block
must already have been computed. So a block’s x
must therefore be computed before its children’s x. That
means the x computation has to go before the
recursive layout call.
On the other hand, an element’s height field depends on
its children’s heights. So while x must be computed
before the recursive call, height has to be
computed after. Similarly, since the y position of
a block depends on its previous sibling’s y position, the
recursive layout calls have to start at the first sibling
and iterate through the list forward.
That is, the layout method should perform its steps in
this order (see Figure 2):
layout is called, it first computes the
width, x, and y fields, reading
from the parent and previous layout
objects.layout methods.layout computes the height field,
reading from the child layout objects.You can see these steps in action in this widget:
This kind of dependency reasoning is crucial to layout and more broadly to any kind of computation on trees. If you get the order of operations wrong, some layout object will try to read a value that hasn’t been computed yet, and the browser will have a bug. We’ll come back to this issue of dependencies in Chapter 16, where it will become even more important.
DocumentLayout needs some layout code too, though since
the document always starts in the same place it’s pretty simple:
class DocumentLayout:
def layout(self):
# ...
self.width = WIDTH - 2*HSTEP
self.x = HSTEP
self.y = VSTEP
child.layout()
self.height = child.heightNote that there’s some padding around the contents—HSTEP
on the left and right, and VSTEP above and below. That’s so
the text won’t run into the very edge of the window and get cut off.
Anyway, with all of the sizes and positions now computed correctly, our browser should display all of the text on the page in the right places.
Formally, computations on a tree like this can be described by an attribute grammar. Attribute grammar engines analyze dependencies between different attributes to determine the right order to traverse the tree and calculate each attribute.
Our layout method is now doing quite a bit of work:
computing sizes and positions; creating child layout objects;
recursively laying out those child layout objects; and aggregating the
display lists so the text can be drawn to the screen. This is a bit
messy, so let’s take a moment to extract just one part of this, the
display list part. Along the way, we can stop copying the display list
contents over and over again as we go up the layout tree.
I think it’s most convenient to do that by adding a
paint function to each layout object, whose return value is
the display list entries for that object. Then there is a separate
function, paint_tree, that recursively calls
paint on all layout objects:
def paint_tree(layout_object, display_list):
display_list.extend(layout_object.paint())
for child in layout_object.children:
paint_tree(child, display_list)For DocumentLayout, there is nothing to paint:
class DocumentLayout:
def paint(self):
return []You can now delete the line that computes a
DocumentLayout’s display_list field.
For a BlockLayout object, we need to copy over the
display_list field that it computes during
recurse and flush:And again, delete the line
that computes a BlockLayout’s display_list
field by copying from child layout objects.
class BlockLayout:
def paint(self):
return self.display_listNow the browser can use paint_tree to collect its own
display_list variable:
class Browser:
def load(self, url):
# ...
self.display_list = []
paint_tree(self.document, self.display_list)
self.draw()Check it out: our browser is now using fancy tree-based layout! I recommend pausing to test and debug. Tree-based layout is powerful but complex, and we’re about to add more features. Stable foundations make for comfortable houses.
Layout trees are common in graphical user interface (GUI) frameworks, but there are other ways to structure layout, such as constraint-based layout. TeX’s boxes and glue and iOS’s auto-layout are two examples of this alternative paradigm.
Browsers use the layout tree a lot,For example, in Chapter 7, we’ll use the size and position of each link to figure out which one the user clicked on. and one simple and visually compelling use case is drawing backgrounds.
Backgrounds are rectangles, so our first task is putting rectangles in the display list. Right now, the display list is a list of words to draw to the screen, but we can conceptualize it instead as a list of commands, of which there is currently only one type. We now want two types of commands:
class DrawText:
def __init__(self, x1, y1, text, font):
self.top = y1
self.left = x1
self.text = text
self.font = font
class DrawRect:
def __init__(self, x1, y1, x2, y2, color):
self.top = y1
self.left = x1
self.bottom = y2
self.right = x2
self.color = colorNow BlockLayout must add DrawText objects
for each word it wants to draw, but only in inline mode:Why not change the
display_list field inside a BlockLayout to
contain DrawText commands directly? I suppose you could,
but I think it’s cleaner to create all of the draw commands in one
place.
class BlockLayout:
def paint(self):
cmds = []
if self.layout_mode() == "inline":
for x, y, word, font in self.display_list:
cmds.append(DrawText(x, y, word, font))
return cmdsBut it can also add a DrawRect command to draw a
background. Let’s add a gray background to pre tags (which
are used for code examples):
class BlockLayout:
def paint(self):
# ...
if isinstance(self.node, Element) and self.node.tag == "pre":
x2, y2 = self.x + self.width, self.y + self.height
rect = DrawRect(self.x, self.y, x2, y2, "gray")
cmds.append(rect)
# ...Make sure this code comes before the loop that adds
DrawText objects: the background has to be drawn
below that text. Note also that paint_tree calls
paint before recursing into the subtree, so the subtree
also paints on top of this background, as desired.
With the display list filled out, we need to draw each
graphics command. Let’s add an execute method for this. On
DrawText it calls create_text:
class DrawText:
def execute(self, scroll, canvas):
canvas.create_text(
self.left, self.top - scroll,
text=self.text,
font=self.font,
anchor='nw')Note that execute takes the scroll amount as a
parameter; this way, each graphics command does the relevant coordinate
conversion itself. DrawRect does the same with
create_rectangle:
class DrawRect:
def execute(self, scroll, canvas):
canvas.create_rectangle(
self.left, self.top - scroll,
self.right, self.bottom - scroll,
width=0,
fill=self.color)By default, create_rectangle draws a one-pixel black
border, which we don’t want for backgrounds, so make sure to pass
width=0.
We still want to skip offscreen graphics commands, so let’s add a
bottom field to DrawText so we know when to
skip those:
def __init__(self, x1, y1, text, font):
# ...
self.bottom = y1 + font.metrics("linespace")The browser’s draw method now just uses top
and bottom to decide which commands to
execute:
class Browser:
def draw(self):
self.canvas.delete("all")
for cmd in self.display_list:
if cmd.top > self.scroll + HEIGHT: continue
if cmd.bottom < self.scroll: continue
cmd.execute(self.scroll, self.canvas)Try your browser on a page—maybe this one—with code snippets on it. You should see each code snippet set off with a gray background.
Here’s one more cute benefit of tree-based layout: we now record the height of the whole page. The browser can use that to avoid scrolling past the bottom:
def scrolldown(self, e):
max_y = max(self.document.height + 2*VSTEP - HEIGHT, 0)
self.scroll = min(self.scroll + SCROLL_STEP, max_y)
self.draw()Note the 2*VSTEP, to account for a VSTEP of
whitespace at the top and bottom of the page.
So those are the basics of tree-based layout! In fact, as we’ll see in the next two chapters, this is just one part of the layout tree’s central role in the browser. But before we get to that, we need to add some styling capabilities to our browser. However, even with layout the browser.engineering homepage looks a bit better—see Figure 3.

The draft CSS Painting API allows pages to extend the display list with new types of commands, implemented in JavaScript. This makes it possible to use CSS for styling with visually complex styling provided by a library.
This chapter was a dramatic rewrite of our browser’s layout engine, so:
Tree-based layout makes it possible to dramatically expand our browser’s styling capabilities. We’ll work on that in the next chapter.
The complete set of functions, classes, and methods in our browser should look something like this:
class URL:
def __init__(url)
def request()
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
FONTS
def get_font(size, weight, style)
WIDTH, HEIGHT
HSTEP, VSTEP
BLOCK_ELEMENTS
class DocumentLayout:
def __init__(node)
def layout()
def paint()
class BlockLayout:
def __init__(node, parent, previous)
def layout_mode()
def layout()
def recurse(tree)
def open_tag(tag)
def close_tag(tag)
def flush()
def word(word)
def paint()
class DrawText:
def __init__(x1, y1, text, font)
def execute(scroll, canvas)
class DrawRect:
def __init__(x1, y1, x2, y2, color)
def execute(scroll, canvas)
def paint_tree(layout_object, display_list)
SCROLL_STEP
class Browser:
def __init__()
def draw()
def load(url)
def scrolldown(e)
5-1 Links bar. At the top and bottom of the web version of
each chapter of this book there is a gray bar naming the chapter and
offering back and forward links. It is enclosed in a
<nav class="links"> tag. Have your browser give this
links bar the light gray background a real browser would.
5-2 Hidden head. There’s a good chance your browser is still
showing scripts, styles, and page titles at the top of every page you
visit. Make it so that the <head> element and its
contents are never displayed. Those elements should still be in the HTML
tree, but not in the layout tree.
5-3 Bullets. Add bullets to list items, which in HTML are
<li> tags. You can make them little squares, located
to the left of the list item itself. Also indent <li>
elements so the text inside the element is to the right of the bullet
point.
5-4 Table of contents. The web version of this book has a
table of contents at the top of each chapter, enclosed in a
<nav id="toc"> tag, which contains a list of links.
Add the text “Table of Contents”, with a gray background, above that
list. Don’t modify the lexer or parser.
5-5 Anonymous block boxes. Sometimes, an element has a mix of text-like and container-like children. For example, in this HTML,
<div><i>Hello, </i><b>world!</b><p>So it began...</p></div>the <div> element has three children: the
<i>, <b>, and
<p> elements. The first two are text-like; the last
is container-like. This is supposed to look like two paragraphs, one for
the <i> and <b> and the second for
the <p>. Make your browser do that. Specifically,
modify BlockLayout so it can be passed a sequence of
sibling nodes, instead of a single node. Then, modify the algorithm that
constructs the layout tree so that any sequence of text-like elements
gets made into a single BlockLayout.
5-6 Run-ins. A “run-in heading” is a heading that is drawn
as part of the next paragraph’s text.The exercise names in this section could be considered
run-in headings. But since browser support for the
display: run-in property is poor, this book actually
doesn’t use it; the headings are actually embedded in the next
paragraph. Modify your browser to render
<h6> elements as run-in headings. You’ll need to
implement the previous exercise on anonymous block boxes, and then add a
special case for <h6> elements.
Did you find this chapter useful?