So far, our browser sees web pages as a stream of open tags, close tags, and text. But HTML is actually a tree, and though the tree structure hasn’t been important yet, it will be central to later features like CSS, JavaScript, and visual effects. So this chapter adds a proper HTML parser and converts the layout engine to use it.
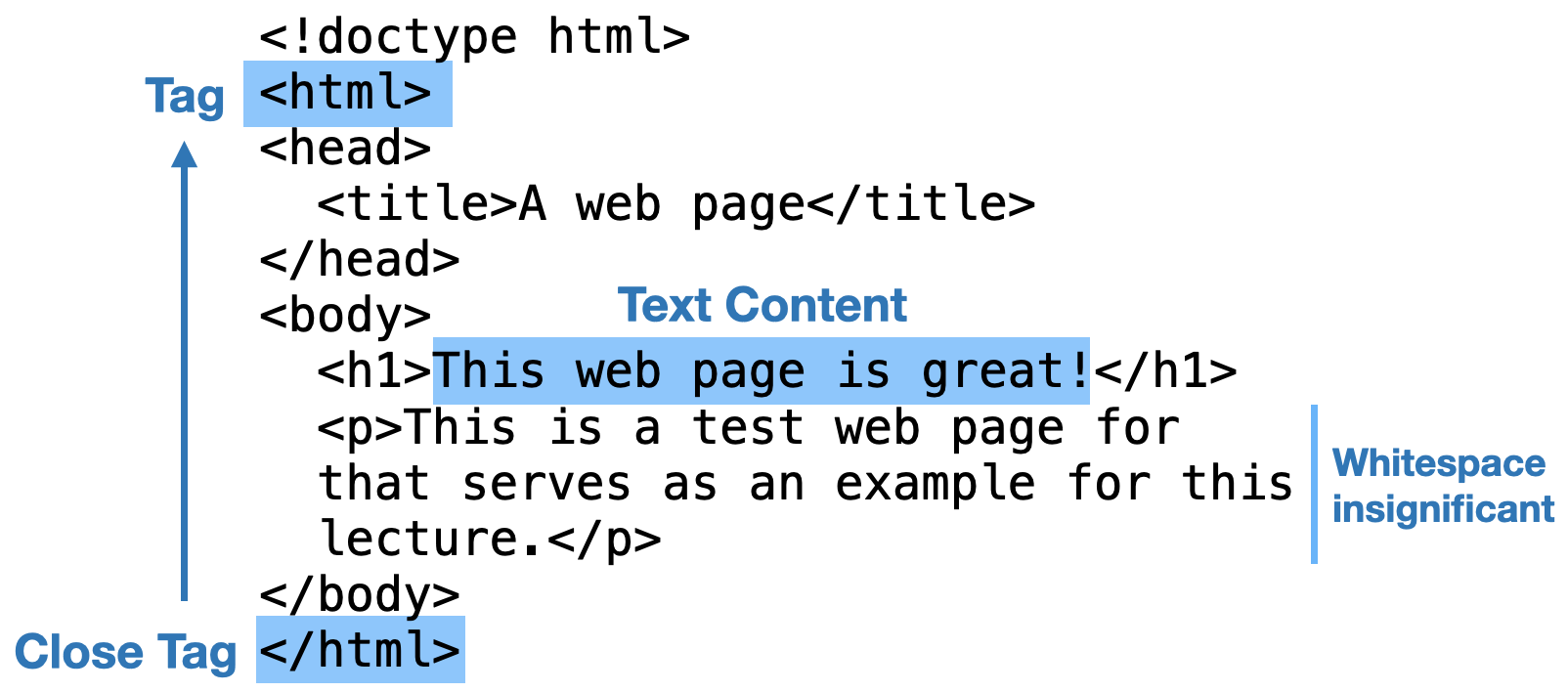
The HTML treeThis is
the tree that is usually called the DOM tree, for Document
Object Model. I’ll keep calling it the HTML tree for
now. has one node for each open and close tag pair and a
node for each span of text.In reality there are other types of nodes too, like
comments, doctypes, CDATA sections, and processing
instructions. There are even some deprecated types! A
simple HTML document showing the structure is shown in Figure 1.
For our browser to use a tree, tokens need to evolve into nodes. That
means adding a list of children and a parent pointer to each one. Here’s
the new Text class, representing text at the leaf of the
tree:
class Text:
def __init__(self, text, parent):
self.text = text
self.children = []
self.parent = parentSince it takes two tags (the open and the close tag) to make a node,
let’s rename the Tag class to Element, and
make it look like this:
class Element:
def __init__(self, tag, parent):
self.tag = tag
self.children = []
self.parent = parentI added a children field to both Text and
Element, even though text nodes never have children, for
consistency.
Constructing a tree of nodes from source code is called parsing. A parser builds a tree one element or text node at a time. But that means the parser needs to store an incomplete tree as it goes. For example, suppose the parser has so far read this bit of HTML:
<html><video></video><section><h1>This is my webpageThe parser has seen five tags (and one text node). The rest of the
HTML will contain more open tags, close tags, and text, but no matter
which tokens it sees, no new nodes will be added to the
<video> tag, which has already been closed. So that
node is “finished”. But the other nodes are unfinished: more children
can be added to the <html>,
<section>, and <h1> nodes,
depending on what HTML comes next—see Figure 2.
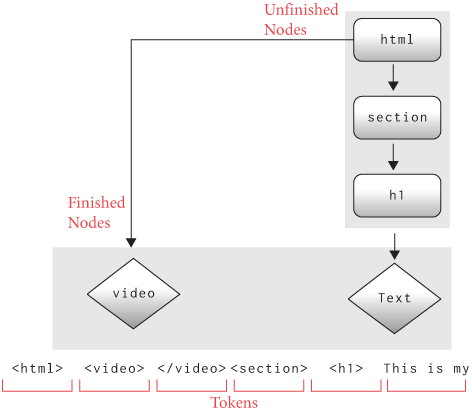
Since the parser reads the HTML file from beginning to end, these unfinished tags are always in a certain part of the tree. The unfinished tags have always been opened but not yet closed; they are always later in the source than the finished nodes; and they are always children of other unfinished tags. To leverage these facts, let’s represent an incomplete tree by storing a list of unfinished tags, ordered with parents before children. The first node in the list is the root of the HTML tree; the last node in the list is the most recent unfinished tag.In Python, and most other languages, it’s faster to add and remove from the end of a list, instead of the beginning.
Parsing is a little more complex than lex, so we’re
going to want to break it into several functions, organized in a new
HTMLParser class. That class can also store the source code
it’s analyzing and the incomplete tree:
class HTMLParser:
def __init__(self, body):
self.body = body
self.unfinished = []Before the parser starts, it hasn’t seen any tags at all, so the
unfinished list storing the tree starts empty. But as the
parser reads tokens, that list fills up. Let’s start that by
aspirationally renaming the lex function we have now to
parse:
class HTMLParser:
def parse(self):
# ...We’ll need to do a bit of surgery on parse. Right now
parse creates Tag and Text
objects and appends them to the out array. We need it to
create Element and Text objects and add them
to the unfinished tree. Since a tree is a bit more complex
than a list, I’ll move the adding-to-a-tree logic to two new methods,
add_text and add_tag.
def parse(self):
text = ""
in_tag = False
for c in self.body:
if c == "<":
in_tag = True
if text: self.add_text(text)
text = ""
elif c == ">":
in_tag = False
self.add_tag(text)
text = ""
else:
text += c
if not in_tag and text:
self.add_text(text)
return self.finish()The out variable is gone, and note that I’ve also moved
the return value to a new finish method, which converts the
incomplete tree to the final, complete tree. So: how do we add things to
the tree?
HTML derives from a long line of document processing systems. Its
predecessor, SGML,
traces back to RUNOFF and is
a sibling to troff, now used for Linux
manual pages. The committee that
standardized SGML now works on the .odf,
.docx, and .epub formats.
Let’s talk about adding nodes to a tree. To add a text node we add it as a child of the last unfinished node:
class HTMLParser:
def add_text(self, text):
parent = self.unfinished[-1]
node = Text(text, parent)
parent.children.append(node)On the other hand, tags are a little more complex since they might be an open or a close tag:
class HTMLParser:
def add_tag(self, tag):
if tag.startswith("/"):
# ...
else:
# ...An open tag adds an unfinished node to the end of the list:
def add_tag(self, tag):
# ...
else:
parent = self.unfinished[-1]
node = Element(tag, parent)
self.unfinished.append(node)A close tag instead finishes the last unfinished node by adding it to the previous unfinished node in the list:
def add_tag(self, tag):
if tag.startswith("/"):
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
# ...Once the parser is done, it turns our incomplete tree into a complete tree by just finishing any unfinished nodes:
class HTMLParser:
def finish(self):
while len(self.unfinished) > 1:
node = self.unfinished.pop()
parent = self.unfinished[-1]
parent.children.append(node)
return self.unfinished.pop()This is almost a complete parser, but it doesn’t quite work at the beginning and end of the document. The very first open tag is an edge case without a parent:
def add_tag(self, tag):
# ...
else:
parent = self.unfinished[-1] if self.unfinished else None
# ...The very last tag is also an edge case, because there’s no unfinished node to add it to:
def add_tag(self, tag):
if tag.startswith("/"):
if len(self.unfinished) == 1: return
# ...Ok, that’s all done. Let’s test our parser out and see how well it works!
The ill-considered JavaScript document.write method
allows JavaScript to modify the HTML source code while it’s being
parsed! This is actually a bad
idea. An implementation of document.write must have the
HTML parser stop to execute JavaScript, but that slows down requests for
images, CSS, and JavaScript used later in the page. To solve this,
modern browsers use speculative
parsing to start loading additional resources even before parsing is
done.
How do we know our parser does the right thing—that it builds the right tree? Well the place to start is seeing the tree it produces. We can do that with a quick, recursive pretty-printer:
def print_tree(node, indent=0):
print(" " * indent, node)
for child in node.children:
print_tree(child, indent + 2)Here we’re printing each node in the tree, and using indentation to
show the tree structure. Since we need to print each node, it’s worth
taking the time to give them a nice printed form, which in Python means
defining the __repr__ function:
class Text:
def __repr__(self):
return repr(self.text)
class Element:
def __repr__(self):
return "<" + self.tag + ">"In general it’s a good idea to define __repr__ methods
for any data objects, and to have those __repr__ methods
print all the relevant fields.
Try this out on the
web page corresponding to this chapter, parsing the HTML source code
and then calling print_tree to visualize it:
body = URL(sys.argv[1]).request()
nodes = HTMLParser(body).parse()
print_tree(nodes)You’ll see something like this at the beginning:
<!doctype html>
'\n'
<html lang="en-US" xml:lang="en-US">
'\n'
<head>
'\n '
<meta charset="utf-8" />Immediately a couple of things stand out. Let’s start at the top,
with the <!doctype html> tag.
This special tag, called a doctype, is always the very first thing in an HTML document. But it’s not really an element at all, nor is it supposed to have a close tag. Our browser won’t be using the doctype for anything, so it’s best to throw it away:Real browsers use doctypes to switch between standards-compliant and legacy parsing and layout modes.
def add_tag(self, tag):
if tag.startswith("!"): return
# ...This ignores all tags that start with an exclamation mark, which not
only throws out doctype declarations but also comments, which in HTML
are written <!-- comment text -->.
Just throwing out doctypes isn’t quite enough though—if you run your
parser now, it will crash. That’s because after the doctype comes a
newline, which our parser treats as text and tries to insert into the
tree. Except there isn’t a tree, since the parser hasn’t seen any open
tags. For simplicity, let’s just have our browser skip whitespace-only
text nodes to side-step the problem:Real browsers retain whitespace to correctly render
make<span></span>up as one word and
make<span> </span>up as two. Our browser won’t.
Plus, ignoring whitespace simplifies later chapters by avoiding a
special case for whitespace-only text tags.
def add_text(self, text):
if text.isspace(): return
# ...The first part of the parsed HTML tree for the
browser.engineering home page now looks something like
this:
<html lang="en-US" xml:lang="en-US">
<head>
<meta charset="utf-8" /="">
<link rel="prefetch" ...>
<link rel="prefetch" ...>Our next problem: why’s everything so deeply indented? Why aren’t these open elements ever closed?
In SGML, document type declarations contained a URL which defined the
valid tags, and in older versions of HTML that was also recommended.
Browsers do use the absence of a document type declaration to identify
very old, pre-SGML versions of HTML,There’s also this crazy thing called “almost standards” or “limited
quirks” mode, due to a backward-incompatible change in table cell
vertical layout. Yes. I don’t need to make these up! but
don’t use the URL, so <!doctype html> is the best
document type declaration for modern HTML.
Elements like <meta> and <link>
are what are called self-closing: these tags don’t surround content, so
you don’t ever write </meta> or
</link>. Our parser needs special support for them.
In HTML, there’s a specific
list of these self-closing tags (the specification calls them “void”
tags):A lot of these
tags are obscure. Browsers also support some additional, obsolete
self-closing tags not listed here, like
keygen.
SELF_CLOSING_TAGS = [
"area", "base", "br", "col", "embed", "hr", "img", "input",
"link", "meta", "param", "source", "track", "wbr",
]Our parser needs to auto-close tags from this list:
def add_tag(self, tag):
# ...
elif tag in self.SELF_CLOSING_TAGS:
parent = self.unfinished[-1]
node = Element(tag, parent)
parent.children.append(node)This code looks right, but it doesn’t quite work right. Why not?
Because our parser is looking for a tag named meta, but
it’s finding a tag named “meta name=...”. The self-closing
code isn’t triggered because the <meta> tag has
attributes.
HTML attributes add information about an element; open tags can have any number of attributes. Attribute values can be quoted, unquoted, or omitted entirely. Let’s focus on basic attribute support, ignoring values that contain whitespace, which are a little complicated.
Since we’re not handling whitespace in values, we can split on whitespace to get the tag name and the attribute–value pairs:
class HTMLParser:
def get_attributes(self, text):
parts = text.split()
tag = parts[0].casefold()
attributes = {}
for attrpair in parts[1:]:
# ...
return tag, attributesHTML tag names are case insensitive, as by the way are attribute
names, so I case-fold them.Lower-casing text is the wrong way to
do case-insensitive comparisons in languages like Cherokee. In HTML
specifically, tag names only use the ASCII characters so lower-casing
them would be sufficient, but I’m using Python’s casefold
function because it’s a good habit to get into. Then,
inside the loop, I split each attribute–value pair into a name and a
value. The easiest case is an unquoted attribute, where an equal sign
separates the two:
def get_attributes(self, text):
# ...
for attrpair in parts[1:]:
if "=" in attrpair:
key, value = attrpair.split("=", 1)
attributes[key.casefold()] = value
# ...The value can also be omitted, like in
<input disabled>, in which case the attribute value
defaults to the empty string:
for attrpair in parts[1:]:
# ...
else:
attributes[attrpair.casefold()] = ""Finally, the value can be quoted, in which case the quotes have to be stripped out:Quoted attributes allow whitespace between the quotes. Parsing that properly requires something like a finite state machine instead of just splitting on whitespace.
if "=" in attrpair:
# ...
if len(value) > 2 and value[0] in ["'", "\""]:
value = value[1:-1]
# ...We’ll store these attributes inside Elements:
class Element:
def __init__(self, tag, attributes, parent):
self.tag = tag
self.attributes = attributes
# ...That means we’ll need to call get_attributes at the top
of add_tag to get the attributes we need to
construct an Element.
def add_tag(self, tag):
tag, attributes = self.get_attributes(tag)
# ...Remember to use tag and attribute instead
of text in add_tag, and try your parser
again:
<html>
<head>
<meta>
<link>
<link>
<link>
<link>
<link>
<meta>It’s close! Yes, if you print the attributes, you’ll see that
attributes with whitespace (like author on one of the
meta tags) are mis-parsed as multiple attributes, and the
final slash on the self-closing tags is incorrectly treated as an extra
attribute. A better parser would fix these issues. But let’s instead
leave our parser as is—these issues aren’t going to be a problem for the
browser we’re building—and move on to integrating it with our
browser.
Putting a slash at the end of self-closing tags, like
<br/>, became fashionable when XHTML looked like it might
replace HTML, and old-timers like me never broke the habit. But unlike
in XML, in HTML
self-closing tags are identified by name, not by some special syntax, so
the slash is optional.
Right now, the Layout class works token by token; we now
want it to go node by node instead. So let’s separate the old
token method into two parts: all the cases for open tags
will go into a new open_tag method and all the cases for
close tags will go into a new close_tag method:The case for text tokens is no
longer needed because our browser can just call the existing
add_text method directly.
class Layout:
def open_tag(self, tag):
if tag == "i":
self.style = "italic"
# ...
def close_tag(self, tag):
if tag == "i":
self.style = "roman"
# ...Now we need the Layout object to walk the node tree,
calling open_tag, close_tag, and
text in the right order:
def recurse(self, tree):
if isinstance(tree, Text):
for word in tree.text.split():
self.word(word)
else:
self.open_tag(tree.tag)
for child in tree.children:
self.recurse(child)
self.close_tag(tree.tag)The Layout constructor can now call recurse
instead of looping through the list of tokens. We’ll also need the
browser to construct the node tree, like this:
class Browser:
def load(self, url):
body = url.request()
self.nodes = HTMLParser(body).parse()
self.display_list = Layout(self.nodes).display_list
self.draw()Run it—the browser should now use the parsed HTML tree.
The doctype syntax is a form of versioning—declaring
which version of HTML the web page is using. But in fact, the
html value for doctype signals not just a
particular version of HTML, but more generally the HTML living
standard.It is
not expected that any new doctype version for HTML will
ever be added again. It’s called a “living standard”
because it changes all the time as features are added. The mechanism for
these changes is simply browsers shipping new features, not any change
to the “version” of HTML. In general, the web is an unversioned
platform—new features are often added as enhancements, but only so
long as they don’t break existing ones.Features can be removed, but
only if they stop being used by the vast majority of sites. This makes
it very hard to remove web features compared with other
platforms.
The parser now handles HTML pages correctly—at least when the HTML is
written by the sorts of goody-two-shoes programmers who remember the
<head> tag, close every open tag, and make their bed
in the morning. Mere mortals lack such discipline and so browsers also
have to handle broken, confusing, headless HTML. In fact,
modern HTML parsers are capable of transforming any string of
characters into an HTML tree, no matter how confusing the markup.Yes, it’s crazy, and for a few
years in the early 2000s the W3C tried to do away with it. They
failed.
The full algorithm is, as you might expect, complicated beyond belief, with dozens of ever-more-special cases forming a taxonomy of human error, but one of its nicer features is implicit tags. Normally, an HTML document starts with a familiar boilerplate:
<!doctype html>
<html>
<head>
</head>
<body>
</body>
</html>In reality, all six of these tags, except the doctype, are
optional: browsers insert them automatically when the web page omits
them. Let’s insert implicit tags in our browser via a new
implicit_tags function. We’ll want to call it in both
add_text and add_tag:
class HTMLParser:
def add_text(self, text):
if text.isspace(): return
self.implicit_tags(None)
# ...
def add_tag(self, tag):
tag, attributes = self.get_attributes(tag)
if tag.startswith("!"): return
self.implicit_tags(tag)
# ...Note that implicit_tags isn’t called for the ignored
whitespace and doctypes. Let’s also call it in finish, to
make sure that an <html> and
<body> tag are created even for empty strings:
class HTMLParser:
def finish(self):
if not self.unfinished:
self.implicit_tags(None)
# ...The argument to implicit_tags is the tag name (or
None for text nodes), which we’ll compare to the list of
unfinished tags to determine what’s been omitted:
class HTMLParser:
def implicit_tags(self, tag):
while True:
open_tags = [node.tag for node in self.unfinished]
# ...implicit_tags has a loop because more than one tag could
have been omitted in a row; every iteration around the loop will add
just one. To determine which implicit tag to add, if any, requires
examining the open tags and the tag being inserted.
Let’s start with the easiest case, the implicit
<html> tag. An implicit <html> tag
is necessary if the first tag in the document is something other than
<html>:
while True:
# ...
if open_tags == [] and tag != "html":
self.add_tag("html")Both <head> and <body> can also
be omitted, but to figure out which it is we need to look at which tag
is being added:
while True:
# ...
elif open_tags == ["html"] \
and tag not in ["head", "body", "/html"]:
if tag in self.HEAD_TAGS:
self.add_tag("head")
else:
self.add_tag("body")Here, HEAD_TAGS lists the tags that you’re supposed to
put into the <head> element:The
<script> tag can go in either the head or the body
section, but it goes into the head by default.
class HTMLParser:
HEAD_TAGS = [
"base", "basefont", "bgsound", "noscript",
"link", "meta", "title", "style", "script",
]Note that if both the <html> and
<head> tags are omitted, implicit_tags
is going to insert both of them by going around the loop twice. In the
first iteration open_tags is [], so the code
adds an <html> tag; then, in the second iteration,
open_tags is ["html"], so it adds a
<head> tag.These add_tag methods themselves call
implicit_tags, which means you can get into an infinite
loop if you forget a case. I’ve been careful to make sure that every tag
added by implicit_tags doesn’t itself trigger more implicit
tags.
Finally, the </head> tag can also be implicit if
the parser is inside the <head> and sees an element
that’s supposed to go in the <body>:
while True:
# ...
elif open_tags == ["html", "head"] and \
tag not in ["/head"] + self.HEAD_TAGS:
self.add_tag("/head")Technically, the </body> and
</html> tags can also be implicit. But since our
finish function already closes any unfinished tags, that
doesn’t need any extra code. So all that’s left for
implicit_tags is to exit out of the loop:
while True:
# ...
else:
breakOf course, there are more rules for handling malformed HTML: formatting tags, nested paragraphs, embedded Scalable Vector Graphics (SVG) and MathML, and all sorts of other complexity. Each has complicated rules abounding with edge cases. But let’s end our discussion of handling author errors here.
The rules for malformed HTML may seem arbitrary, and they are: they evolved over years of trying to guess what people “meant” when they wrote that HTML, and are now codified in the HTML parsing standard. Of course, sometimes these rules “guess” wrong—but as so often happens on the web, it’s more important that every browser does the same thing, rather than each trying to guess what the right thing is.
And now for the payoff! Figure 3 shows a screenshot of this book’s website, loaded in our own browser.To be fair, it actually looks about the same with the Chapter 3 browser.

Thanks to implicit tags, you can mostly skip the
<html>, <body>, and
<head> elements, and they’ll be implicitly added back
for you. In fact, the HTML parser’s many
states guarantee something stricter than that: every HTML document
has exactly one <head> and one
<body>, in the expected order.At least, per document. An
HTML file that uses frames or templates can have more than one
<head> and <body>, but they
correspond to different documents.
This chapter taught our browser that HTML is a tree, not just a flat list of tokens. We added:
The tree structure of HTML is essential to display visually complex web pages, as we will see in the next chapter.
The complete set of functions, classes, and methods in our browser should look something like this:
class URL:
def __init__(url)
def request()
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
FONTS
def get_font(size, weight, style)
WIDTH, HEIGHT
HSTEP, VSTEP
class Layout:
def __init__(tree)
def recurse(tree)
def open_tag(tag)
def close_tag(tag)
def flush()
def word(word)
SCROLL_STEP
class Browser:
def __init__()
def draw()
def load(url)
def scrolldown(e)
4-1 Comments. Update the HTML lexer to support comments.
Comments in HTML begin with <!-- and end with
-->. However, comments aren’t the same as tags: they can
contain any text, including left and right angle brackets. The lexer
should skip comments, not generating any token at all. Check: is
<!--> a comment, or does it just start one?
4-2 Paragraphs. It’s not clear what it would mean for one
paragraph to contain another. Change the parser so that a document like
<p>hello<p>world</p> results in two
sibling paragraphs instead of one paragraph inside another; real
browsers do this too. Do the same for <li> elements,
but make sure nested lists are still possible.
4-3 Scripts. JavaScript code embedded in a
<script> tag uses the left angle bracket to mean
“less than”. Modify your lexer so that the contents of
<script> tags are treated specially: no tags are
allowed inside <script>, except the
</script> close tag.Technically it’s just
</script followed by a space,
tab, \v, \r, slash, or greater than sign.
If you need to talk about </script> tags inside
JavaScript code, you have to split it into multiple
strings.
4-4 Quoted attributes. Quoted attributes can contain spaces
and right angle brackets. Fix the lexer so that this is supported
properly. Hint: the current lexer is a finite state machine, with two
states (determined by in_tag). You’ll need more states.
4-5 Syntax highlighting. Implement the
view-source protocol as in Exercise 1-5, but make it
syntax-highlight the source code of HTML pages. Keep source code for
HTML tags in a normal font, but make text contents bold. If you’ve
implemented it, wrap text in <pre> tags as well to
preserve line breaks. Hint: subclass the HTML parser and use it to
implement your syntax highlighter.
4-6 Mis-nested formatting tags. Extend your HTML parser to
support markup like
<b>Bold <i>both</b> italic</i>.
This requires keeping track of the set of open text formatting elements
and inserting implicit open and close tags when text formatting elements
are closed in the wrong order. The bold/italic example, for example,
should insert an implicit </i> before the
</b> and an implicit <i> after
it.
Did you find this chapter useful?