The first web applications were like the previous chapter’s guest book, with the server generating new web pages for every user action. But in the early 2000s, JavaScript-enhanced web applications, which can update pages dynamically and respond immediately to user actions, took their place. Let’s add support for this key web technology to our browser.
Actually writing a JavaScript interpreter is beyond the scope of this
book,But check out a
book on programming language implementation if it sounds
interesting! so this chapter uses the dukpy
library for executing JavaScript.
DukPy wraps a JavaScript interpreter called Duktape. The most famous JavaScript interpreters are those used in browsers: SpiderMonkey (Firefox), JavaScriptCore (Safari), and V8 (Chrome). Unlike those implementations, which are extremely fast but also extremely complex, Duktape aims to be simple and extensible, and is usually embedded inside a larger C or C++ project.For example, in a video game the high-speed graphics code is usually written in C or C++ , but the actual plot of the game is usually written in a higher-level language like JavaScript.
Like other JavaScript engines, DukPy not only executes JavaScript code, but also allows it to call exported Python functions. We’ll be using this feature to allow JavaScript code to modify the web page it’s running on.
The first step to using DukPy is installing it. On most machines, including on Windows, macOS, and Linux systems, you should be able to do this with:
python3 -m pip install dukpyIf you have a really old version of Python, you might need to install
the pip package first, possibly using a command line
easy_install. If you do your Python programming through an
integrated development environment (IDE), you may need to use your IDE’s
package installer. If nothing else works, you can build from source.
If you’re following along in something other than Python, you might
need to skip this chapter, though you could try binding directly to the
duktape library that dukpy uses.
To test whether you installed DukPy correctly, execute this:
import dukpy
dukpy.evaljs("2 + 2")If you get an error on the first line, you probably failed to install DukPy.Or, on my Linux machine, I sometimes get errors due to file ownership. You may have to do some sleuthing. If you get an error, or a segfault, on the second line, there’s a chance that Duktape failed to compile, or maybe doesn’t support your system, and you might need to debug further.
Note to JavaScript experts: DukPy does not implement newer syntax
like let and const or arrow functions. In
keeping with this book’s aesthetics, you’ll need to use old-school
JavaScript from the turn of the century.
The test above shows how you run JavaScript code in DukPy: you just
call evaljs! Let’s put this newfound knowledge to work in
our browser.
On the web, JavaScript is found in <script> tags.
Normally, a <script> tag has a src
attribute with a relative URL that points to a JavaScript file, much
like with CSS files. A <script> tag could also
contain JavaScript source code between the start and end tag, but we
won’t implement that.It’s a challenge for parsing, since it’s hard to avoid
less-than and greater-than signs in JavaScript code. See Exercise 4-3.
Finding and downloading those scripts is similar to what we did for CSS. First, we need to find all of the scripts:
class Tab:
def load(self, url, payload=None):
# ...
scripts = [node.attributes["src"] for node
in tree_to_list(self.nodes, [])
if isinstance(node, Element)
and node.tag == "script"
and "src" in node.attributes]
# ...Next, we run all of the scripts:
def load(self, url, payload=None):
# ...
for script in scripts:
script_url = url.resolve(script)
try:
body = script_url.request()
except:
continue
print("Script returned: ", dukpy.evaljs(body))
# ...This should run before styling and layout. To try it out, create a
simple web page with a script tag:
<script src=test.js></script>Then write a super simple script to test.js, maybe
this:
var x = 2
x + xPoint your browser at that page, and you should see:
Script returned: 4That’s your browser running its first bit of JavaScript!
Actually, real browsers run JavaScript code as soon as the browser
parses the <script> tag, not after the whole
page is parsed. Or, at least, that is the default; there are many
options. What our browser does is what a real browser does when the
defer
attribute is set. The default behavior is much
trickier to implement efficiently.
Right now, our browser just prints the last expression in a script;
but in a real browser scripts must call the console.log
function to print. To support that, we will need to export a
function from Python into JavaScript. We’ll be exporting a lot of
functions, so to avoid polluting the Tab object with many
new methods, let’s put this code in a new JSContext
class:
class JSContext:
def __init__(self):
self.interp = dukpy.JSInterpreter()
def run(self, code):
return self.interp.evaljs(code)DukPy’s JSInterpreter object stores the values of all
the JavaScript variables, and lets us run multiple JavaScript snippets
and share variable values and other state between them.
We create this new JSContext object while loading the
page:
class Tab:
def load(self, url, payload=None):
# ...
self.js = JSContext()
for script in scripts:
# ...
self.js.run(body)As a side benefit of using one JSContext for all
scripts, it is now possible to run two scripts and have one of them
define a variable that the other uses, say on a page like this:
<script src=a.js></script>
<script src=b.js></script>Suppose a.js is “var x = 2;” and
b.js is “console.log(x + x)”; the variable
x is set in a.js but used in
b.js. In real web browsers, that’s common, since one script
might define library functions that another script wants to call.
Now, to allow JavaScript to interact with the outside world, DukPy
allows us to “export” functions to it. For example, we can export
Python’s print function like so:
class JSContext:
def __init__(self):
# ...
self.interp.export_function("log", print)We can call an exported function from JavaScript using DukPy’s
call_python function. For example:
call_python("log", "Hi from JS")When this JavaScript code runs, DukPy converts the JavaScript string
"Hi from JS" into a Python string,This conversion works for
numbers, strings, and booleans, plus arrays and dictionaries thereof,
but not with fancy objects. and then passes that Python
string to the print function we exported. Then
print prints that string.
Since we ultimately want a console.log
function, not a call_python function, we need to define a
console object and then give it a log
property. We can do that in JavaScript:
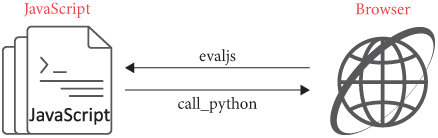
console = { log: function(x) { call_python("log", x); } }In case you’re not too familiar with JavaScript,Now’s a good time to brush
up! this defines a variable called
console, whose value is an object literal with the property
log, whose value is a function that calls
call_python. The interaction between the browser and
JavaScript is shown in Figure 1.
We can call that JavaScript code our “JavaScript runtime”; we run it
before we run any user code, so let’s stick it in a
runtime.js file and execute it when the
JSContext is created, before we run any user code:
RUNTIME_JS = open("runtime.js").read()
class JSContext:
def __init__(self):
# ...
self.interp.evaljs(RUNTIME_JS)Now you should be able to put console.log("Hi from JS!")
into a JavaScript file, run it from your browser, and see output in your
terminal. You should also be able to call console.log
multiple times.
Taking a step back, when we run JavaScript in our browser, we’re mixing C code, which implements the JavaScript interpreter; Python code, which implements certain JavaScript functions; a JavaScript runtime, which wraps the Python API to look more like the JavaScript one; and of course some user code in JavaScript. There’s a lot of complexity here!
If a script runs for a long time, or has an infinite loop, our browser locks up and becomes completely unresponsive to the user. This is a consequence of JavaScript’s single-threaded semantics and its task-based, run-to-completion scheduling. Some APIs like Web Workers allow limited multithreading, but those threads don’t have access to the DOM.
Crashes in JavaScript code are frustrating to debug. You can cause a crash by writing bad code, or by explicitly raising an exception, like so:
throw Error("bad");When a web page runs some JavaScript that crashes, the browser should
ignore the crash. Web pages shouldn’t be able to crash our browser! You
can implement that like this (plus changing the call site of
run to pass the script):
class JSContext:
def run(self, script, code):
try:
return self.interp.evaljs(code)
except dukpy.JSRuntimeError as e:
print("Script", script, "crashed", e)But as you go through this chapter, you’ll also run into another type of crash: crashes in our own JavaScript runtime. We can’t ignore those, because that’s our code. Debugging these crashes is a bear: by default DukPy won’t show a backtrace, and if the runtime code calls into an exported function that crashes it gets even more confusing.
Here are a few tips to help with these crashes. First, if you get a crash inside some JavaScript function, wrap the body of the function like this:
function foo() {
try {
// ...
} catch(e) {
console.log("Crash in function foo()", e.stack);
throw e;
}
}This code catches all exceptions and prints a stack trace before re-raising them. If you instead are getting crashes inside an exported function you will need to wrap that function, on the Python side:
class JSContext:
def foo(self, arg):
try:
# ...
except:
import traceback
traceback.print_exc()
raiseDebugging these issues is not easy, because all these calls between Python and JavaScript get pretty complicated. Because these bugs are hard, it’s worth approaching debugging systematically and gathering a lot of information before attempting a fix.
Early web browsers offered about this support for JavaScript debugging! Today’s sophisticated developer tools came together bit by bit. Microsoft’s Script Debugger introduced a step debugger for JavaScript,Which it called JScript for trademark reasons. Firebug introduced a JS Console and the Network tab, and Webkit’s Web Inspector the “Inspect” button and DOM view. These features were so useful they quickly became standard and are now a core part of every browser engine.
So far, JavaScript evaluation is fun but useless, because JavaScript can’t make any kinds of modifications to the page itself. (Why even run JavaScript if it can’t do anything besides print? Who looks at a browser’s console output?) We need to allow JavaScript to modify the page.
JavaScript manipulates a web page by calling any of a large set of methods collectively called the DOM API. The DOM API is big, and it keeps getting bigger, so we won’t be implementing all, or even most, of it. But a few core functions show key elements of the full API:
querySelectorAll returns all the elements matching a
selector;getAttribute returns an element’s value for some
attribute; andinnerHTML replaces the content of an element with new
HTML.We’ll implement simplified versions of these APIs.The simplifications will be
minor. querySelectorAll will return an array, not this
thing called a NodeList; innerHTML will only
write the HTML contents of an element, and won’t allow reading those
contents. This suffices to demonstrate JavaScript–browser
interaction.
Let’s start with querySelectorAll. First, export a
function:
class JSContext:
def __init__(self):
# ...
self.interp.export_function("querySelectorAll",
self.querySelectorAll)
# ...In JavaScript, querySelectorAll is a method on the
document object, which we need to define in the JavaScript
runtime:
document = { querySelectorAll: function(s) {
return call_python("querySelectorAll", s);
}}On the Python side, querySelectorAll first has to parse
the selector and then find and return the matching elements. To parse
the selector, I’ll call into the CSSParser’s
selector method:If you pass querySelectorAll an invalid
selector, the selector call will throw an error, and DukPy
will convert that Python-side exception into a JavaScript-side exception
in the web script we are running, which can catch it.
class JSContext:
def querySelectorAll(self, selector_text):
selector = CSSParser(selector_text).selector()Next we need to find and return all matching elements. To do that, we
need the JSContext to have access to the Tab,
specifically to its nodes field. So let’s pass in the
Tab when creating a JSContext:
class JSContext:
def __init__(self, tab):
self.tab = tab
# ...
class Tab:
def load(self, url, payload=None):
# ...
self.js = JSContext(self)
# ...Now querySelectorAll will find all nodes matching the
selector:
def querySelectorAll(self, selector_text):
# ...
nodes = [node for node
in tree_to_list(self.tab.nodes, [])
if selector.matches(node)]Finally, we need to return those nodes back to JavaScript. You might try something like this:
def querySelectorAll(self, selector_text):
# ...
return nodesHowever, this throws an error:Yes, that’s a confusing error message. Is it a
JSRuntimeError, an EvalError, or a
TypeError? The confusion is a consequence of the complex
interaction of Python, JS, and C code. (JSON, or JavaScript Object
Notation, is a language-independent data format.)
_dukpy.JSRuntimeError: EvalError:
Error while calling Python Function:
TypeError('Object of type Element is not JSON serializable')What DukPy is trying to tell you is that it has no idea what to do
with the Element objects that querySelectorAll
returns. After all, the Element class only exists in
Python, not JavaScript!
Python objects need to stay on the Python side of the browser, so JavaScript code will need to refer to them via some kind of indirection. I’ll use a simple numeric identifier, which I’ll call a handle (see Figure 2).Note the similarity to file descriptors, which give user-level applications access to kernel data structures.
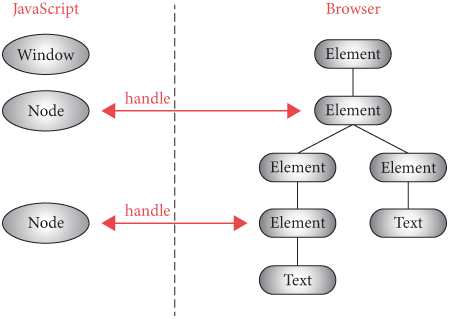
We’ll need to keep track of the handle to node mapping. Let’s create
a node_to_handle data structure to map nodes to handles,
and a handle_to_node map that goes the other way:
class JSContext:
def __init__(self, tab):
# ...
self.node_to_handle = {}
self.handle_to_node = {}
# ...Now the querySelectorAll handler can allocate handles
for each node and return those handles instead:
def querySelectorAll(self, selector_text):
# ...
return [self.get_handle(node) for node in nodes]The get_handle function should create a new handle if
one doesn’t exist yet:
class JSContext:
def get_handle(self, elt):
if elt not in self.node_to_handle:
handle = len(self.node_to_handle)
self.node_to_handle[elt] = handle
self.handle_to_node[handle] = elt
else:
handle = self.node_to_handle[elt]
return handleSo now the querySelectorAll handler returns something
like [1, 3, 4, 7], with each number being a handle for an
element, which DukPy can easily convert into JavaScript objects without
issue. Now of course, on the JavaScript side,
querySelectorAll shouldn’t return a bunch of numbers: it
should return a list of Node objects.In a real browser,
querySelectorAll actually returns a NodeList
object, for kind of abstruse reasons that aren’t relevant
here. So let’s define a Node object in our
runtime that wraps a handle:If your JavaScript is rusty, you might want to read up on
the crazy way you define classes in JavaScript. Modern JavaScript also
provides the class syntax, which is more sensible, but it’s
not supported in DukPy.
function Node(handle) { this.handle = handle; }We create these Node objects in
querySelectorAll’s wrapper:This code creates new
Node objects every time you call
querySelectorAll, even if there’s already a
Node for that handle. That means you can’t use equality to
compare Node objects. I’ll ignore that but a real browser
wouldn’t.
document = { querySelectorAll: function(s) {
var handles = call_python("querySelectorAll", s);
return handles.map(function(h) { return new Node(h) });
}}Early browsers didn’t offer querySelectorAll, only
getElementById and getElementsByTagName, and
the earliest
versions of querySelectorAll were JavaScript
re-implementations, especially in the popular and influential jQuery library. But since browsers
already implement CSS selectors, it only makes sense to expose
that implementation to JavaScript directly.
Now that we’ve got some Nodes, what can we do with
them?
One simple DOM method is getAttribute, a method on
Node objects that lets you get the value of HTML
attributes. Implementing getAttribute means solving the
opposite problem to querySelectorAll: taking
Node objects on the JavaScript side, and shipping them over
to Python.
The solution is similar to querySelectorAll: instead of
shipping the Node object itself, we send over its
handle:
Node.prototype.getAttribute = function(attr) {
return call_python("getAttribute", this.handle, attr);
}On the Python side, the getAttribute function takes two
arguments, a handle and an attribute:
class JSContext:
def getAttribute(self, handle, attr):
elt = self.handle_to_node[handle]
attr = elt.attributes.get(attr, None)
return attr if attr else ""Note that if the attribute is not assigned, the get
method will return None, which DukPy will translate to
JavaScript’s null. Don’t forget to export this function as
getAttribute.
We finally have enough of the DOM API to implement a little character count function for text areas:
inputs = document.querySelectorAll('input')
for (var i = 0; i < inputs.length; i++) {
var name = inputs[i].getAttribute("name");
var value = inputs[i].getAttribute("value");
if (value.length > 100) {
console.log("Input " + name + " has too much text.")
}
}Ideally, though we’d update the character count every time the user types into an input box. That requires running JavaScript on every key press. Let’s implement that next.
Node objects in the DOM correspond to
Element nodes in the browser. They thus have JavaScript
object properties as well as HTML attributes. They’re
easy to confuse, and to make matters worse, many DOM object properties
reflect
attribute values automatically. For example, the id
property on Node objects gives read-write access to the id
attribute of the underlying Element. This is very
convenient, and avoids calling setAttribute and
getAttribute all over the place. But this reflection only
applies to certain fields; setting made-up JavaScript properties won’t
create corresponding HTML attributes, nor vice versa.
The browser executes JavaScript code as soon as it loads the web page, but that code often wants to change the page in response to user actions.
Here’s how that works. Any time the user interacts with the page, the
browser generates events. Each event has a type, like
change, click, or submit, and
happens at a target element. The addEventListener
method allows JavaScript to react to those events:
node.addEventListener('click', func) sets func
to run every time the element corresponding to node
generates a click event. It’s basically Tk’s
bind, but in the browser—see Figure 3. Let’s implement
it.
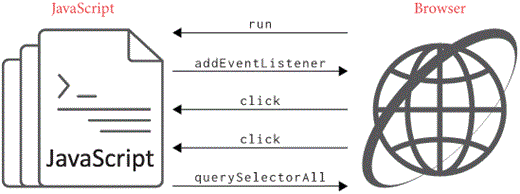
Let’s start with generating events. I’ll create a
dispatch_event method and call it whenever an event is
generated. That includes, first of all, any time we click in the
page:
class Tab:
def click(self, x, y):
# ...
elif elt.tag == "a" and "href" in elt.attributes:
self.js.dispatch_event("click", elt)
# ...
elif elt.tag == "input":
self.js.dispatch_event("click", elt)
# ...
elif elt.tag == "button":
self.js.dispatch_event("click", elt)
# ...
# ...Second, before updating input area values:
class Tab:
def keypress(self, char):
if self.focus:
self.js.dispatch_event("keydown", self.focus)
# ...And finally, when submitting forms but before actually sending the request to the server:
def submit_form(self, elt):
self.js.dispatch_event("submit", elt)
# ...So far so good—but what should the dispatch_event method
do? Well, it needs to run listeners passed to
addEventListener, so those need to be stored somewhere.
Since those listeners are JavaScript functions, we need to keep that
data on the JavaScript side, in a variable in the runtime. I’ll call
that variable LISTENERS; we’ll use it to look up handles
and event types, so let’s make it map handles to a dictionary that maps
event types to a list of listeners:
LISTENERS = {}
Node.prototype.addEventListener = function(type, listener) {
if (!LISTENERS[this.handle]) LISTENERS[this.handle] = {};
var dict = LISTENERS[this.handle];
if (!dict[type]) dict[type] = [];
var list = dict[type];
list.push(listener);
}To dispatch an event, we need to look up the type and handle in the
LISTENERS array, like this:
Node.prototype.dispatchEvent = function(type) {
var handle = this.handle;
var list = (LISTENERS[handle] && LISTENERS[handle][type]) || [];
for (var i = 0; i < list.length; i++) {
list[i].call(this);
}
}Note that dispatchEvent uses the call
method on functions, which sets the value of this inside
that function. As is standard in JavaScript, I’m setting it to the node
that the event was generated on.
When an event occurs, the browser calls dispatchEvent
from Python:
class JSContext:
def dispatch_event(self, type, elt):
handle = self.node_to_handle.get(elt, -1)
self.interp.evaljs(
EVENT_DISPATCH_JS, type=type, handle=handle)Here, the EVENT_DISPATCH_JS constant is a string of
JavaScript code that dispatches a new event:
EVENT_DISPATCH_JS = \
"new Node(dukpy.handle).dispatchEvent(dukpy.type)"So when dispatch_event is called on the Python side,
that runs dispatchEvent on the JavaScript side, and that in
turn runs all of the event listeners. The dukpy JavaScript
object in this code snippet stores the named type and
handle arguments to evaljs.
With all this event-handling machinery in place, we can update the character count every time an input area changes:
function lengthCheck() {
var name = this.getAttribute("name");
var value = this.getAttribute("value");
if (value.length > 100) {
console.log("Input " + name + " has too much text.")
}
}var inputs = document.querySelectorAll("input");
for (var i = 0; i < inputs.length; i++) {
inputs[i].addEventListener("keydown", lengthCheck);
}Note that lengthCheck uses this to
reference the input element that actually changed, as set up by
dispatchEvent.
So far so good—but ideally the length check wouldn’t print to the console; it would add a warning to the web page itself. To do that, we’ll need to not only read from the page but also modify it.
JavaScript first
appeared in 1995, as part of Netscape Navigator. Its name was chosen
to indicate a similarity to the Java
language, and the syntax is Java-esque for that reason. However, under
the surface JavaScript is a much more dynamic language than Java, as is
appropriate given its role as a progressive enhancement mechanism for
the web. For example, any method or property on any object (including
built-in ones like Element) can be dynamically overridden
at any time. This makes it possible to polyfill
differences between browsers, adding features that look built-in to
other JavaScript code.
So far we’ve implemented read-only DOM methods; now we need methods
that change the page. The full DOM API provides a lot of such methods,
but for simplicity I’m going to implement only innerHTML,
which is used like this:
node.innerHTML = "This is my <b>new</b> bit of content!";In other words, innerHTML is a property of node
objects, with a setter that is run when the field is modified.
That setter takes the new value, which must be a string, parses it as
HTML, and makes the new, parsed HTML nodes children of the original
node.
Let’s implement this, starting on the JavaScript side. JavaScript has
the obscure Object.defineProperty function to define
setters, which DukPy supports:
Object.defineProperty(Node.prototype, 'innerHTML', {
set: function(s) {
call_python("innerHTML_set", this.handle, s.toString());
}
});In innerHTML_set, we’ll need to parse the HTML string.
That turns out to be trickier than you’d think, because our browser’s
HTML parser is intended to parse whole HTML documents, not these
document fragments. As an expedient, close-enough hack,Real browsers follow the standardized
parsing algorithm for HTML fragments. I’ll just wrap
the HTML in an html and body element:
def innerHTML_set(self, handle, s):
doc = HTMLParser("<html><body>" + s + "</body></html>").parse()
new_nodes = doc.children[0].childrenDon’t forget to export the innerHTML_set function. Note
that we extract all children of the body element, because
an innerHTML_set call can create multiple nodes at a time.
These new nodes must now be made children of the element
innerHTML_set was called on:
def innerHTML_set(self, handle, s):
# ...
elt = self.handle_to_node[handle]
elt.children = new_nodes
for child in elt.children:
child.parent = eltWe update the parent pointers of those parsed child nodes because
otherwise they would point to the dummy body element that
we added to aid parsing.
It might look like we’re done—but try this out and you’ll realize
that nothing happens when a script calls innerHTML_set.
That’s because, while we have changed the HTML tree, we haven’t
regenerated the layout tree or the display list, so the browser is still
showing the old page.
Whenever the page changes, we need to update its rendering by calling
render:Redoing layout for the whole page is often wasteful; Chapter 16 explores a more complicated
algorithm that speeds this up.
class JSContext:
def innerHTML_set(self, handle, s):
# ...
self.tab.render()JavaScript can now modify the web page!Note that while rendering will update to account for the new HTML, any added scripts or style sheets will not properly load, and removed style sheets will (incorrectly) still apply. I’ve left fixing that as Exercise 9-7.
Let’s try this out in our guest book. Say we want a 100-character limit on guest book entries to prevent long, incoherent rants from making it in.
First, switch to the server codebase and add a
<strong> after the guest book form. Initially this
element will be empty, but we’ll write an error message into it if the
paragraph gets too long.
def show_comments():
# ...
out += "<strong></strong>"
# ...Also add a script to the page.
def show_comments():
# ...
out += "<script src=/comment.js></script>"
# ...Now the browser will request comment.js, so our server
needs to serve that JavaScript file:
def do_request(method, url, headers, body):
# ...
elif method == "GET" and url == "/comment.js":
with open("comment.js") as f:
return "200 OK", f.read()
# ...We can then put our little input length checker into
comment.js, with the lengthCheck function
modified to use innerHTML:
var strong = document.querySelectorAll("strong")[0];
function lengthCheck() {
var value = this.getAttribute("value");
if (value.length > 100) {
strong.innerHTML = "Comment too long!";
}
}
var inputs = document.querySelectorAll("input");
for (var i = 0; i < inputs.length; i++) {
inputs[i].addEventListener("keydown", lengthCheck);
}Try it out: write a long comment and you should see the page warning
you when it grows too long. By the way, we might want to make it stand
out more, so let’s go ahead and add another URL to our web server,
/comment.css, with the contents:
strong { font-weight: bold; color: red; }Add a link to the guest book page so that this style
sheet is loaded.
But even though we tell the user that their comment is too long the user can submit the guest book entry anyway. Oops! Let’s fix that.
This code has a subtle memory leak: if you access an HTML element
from JavaScript (thereby creating a handle for it) and then remove the
element from the page (using innerHTML), Python won’t be
able to garbage-collect the Element object because it is
still stored in the node_to_handle map. And that’s good, if
JavaScript can still access that Element via its handle,
but bad otherwise. Solving this is quite tricky, because it requires the
Python and JavaScript garbage collectors to cooperate.
So far, when an event is generated, the browser will run the listeners, and then also do whatever it normally does for that event—the default action. I’d now like JavaScript code to be able to cancel that default action.
There are a few steps involved. First of all, event listeners should
receive an event object as an argument. That object should have
a preventDefault method. When that method is called, the
default action shouldn’t occur.
First of all, we’ll need event objects. Back to our JavaScript runtime:
function Event(type) {
this.type = type
this.do_default = true;
}
Event.prototype.preventDefault = function() {
this.do_default = false;
}Note the do_default field, to record whether
preventDefault has been called. We’ll now be passing an
Event object to dispatchEvent, instead of just
the event type:
Node.prototype.dispatchEvent = function(evt) {
var type = evt.type;
// ...
for (var i = 0; i < list.length; i++) {
list[i].call(this, evt);
}
// ...
return evt.do_default;
}In Python, we now need to create an Event to pass to
dispatchEvent:
EVENT_DISPATCH_JS = \
"new Node(dukpy.handle).dispatchEvent(new Event(dukpy.type))"Also note that dispatchEvent returns
evt.do_default, which is not only standard in JavaScript
but also helpful when dispatching events from Python, because Python’s
dispatch_event can return that boolean to its handler:
class JSContext:
def dispatch_event(self, type, elt):
# ...
do_default = self.interp.evaljs(
EVENT_DISPATCH_JS, type=type, handle=handle)
return not do_defaultThis way, every time an event happens, the browser can check the
return value of dispatch_event and stop if it is
True. We have three such places in the click
method:
class Tab:
def click(self, x, y):
while elt:
# ...
elif elt.tag == "a" and "href" in elt.attributes:
if self.js.dispatch_event("click", elt): return
# ...
elif elt.tag == "input":
if self.js.dispatch_event("click", elt): return
# ...
elif elt.tag == "button":
if self.js.dispatch_event("click", elt): return
# ...
# ...
# ...And one in submit_form:
class Tab:
def submit_form(self, elt):
if self.js.dispatch_event("submit", elt): returnAnd one in keypress:
class Tab:
def keypress(self, char):
if self.focus:
if self.js.dispatch_event("keydown", self.focus): returnNow our character count code can prevent the user from submitting a form: it can use a global variable to track whether or not submission is allowed, and then when submission is attempted it can check that variable and cancel that submission if necessary:
var allow_submit = true;
function lengthCheck() {
// ...
allow_submit = value.length <= 100;
if (!allow_submit) {
// ...
}
}
var form = document.querySelectorAll("form")[0];
form.addEventListener("submit", function(e) {
if (!allow_submit) e.preventDefault();
});This way it’s impossible to submit the form when the comment is too long!
Well … impossible in this browser. But since there are browsers that don’t run JavaScript (like ours, one chapter back), we should check the length on the server side too:
def add_entry(params):
if 'guest' in params and len(params['guest']) <= 100:
ENTRIES.append(params['guest'])Note that we shouldn’t—can’t—rely on JavaScript being executed by the browser, because the browser is the user’s agent, not ours. Ideally, web pages should be written so that they work correctly without JavaScript, but work better with it. This is called progressive enhancement, and it means we’re not replicating in JavaScript what the browser can already do.
A closing thought: while our guest book now has a little bit of JavaScript code, it’s still mostly HTML, CSS, form elements, other standard web features. In this way JavaScript extends the web instead of replacing it. This is in contrast to the recently departed Adobe Flash, and before that Java Applets, which were self-contained plug-ins that handled input and rendering on their own.
Search engines are constantly crawling the web and indexing all of the web pages they can find. In the early days, indexing was just a matter of loading the HTML, parsing it and extracting the information. But these days, a lot of single-page app sites use JavaScript to “hydrate”This process is called “hydration” by analogy with how water is added to dehydrated food to make it edible again. their site into its full contents. On such sites, before hydration happens, the information in the site is hidden inside of JavaScript data structures. For this reason, search engines need to not just parse HTML, but also run JavaScript (and load style sheets) during indexing. In other words, the indexing systems use browsers (such as, for example, headless Chrome)—one more place browsers appear in the web ecosystem.
Our browser now runs JavaScript applications on behalf of websites. Granted, it supports just four methods from the vast DOM API, but even those demonstrate:
A web page can now add functionality via a clever script, instead of waiting for a browser developer to add it into the browser itself. And as a side benefit, a web page can now earn the lofty title of “web application”.
Starting with this chapter, I won’t be able to inline the chapter’s browser into an iframe, due to security restrictions related to the way I’m communicating with scripts within the web page. But you can still load it in a new browser tab by clicking here.
The complete set of functions, classes, and methods in our browser should now look something like this:
class URL:
def __init__(url)
def request(payload)
def resolve(url)
def __str__()
class Text:
def __init__(text, parent)
def __repr__()
class Element:
def __init__(tag, attributes, parent)
def __repr__()
def print_tree(node, indent)
def tree_to_list(tree, list)
class HTMLParser:
SELF_CLOSING_TAGS
HEAD_TAGS
def __init__(body)
def parse()
def get_attributes(text)
def add_text(text)
def add_tag(tag)
def implicit_tags(tag)
def finish()
class CSSParser:
def __init__(s)
def whitespace()
def literal(literal)
def word()
def ignore_until(chars)
def pair()
def selector()
def body()
def parse()
class TagSelector:
def __init__(tag)
def matches(node)
class DescendantSelector:
def __init__(ancestor, descendant)
def matches(node)
FONTS
def get_font(size, weight, style)
DEFAULT_STYLE_SHEET
INHERITED_PROPERTIES
def style(node, rules)
def cascade_priority(rule)
WIDTH, HEIGHT
HSTEP, VSTEP
class Rect:
def __init__(left, top, right, bottom)
def contains_point(x, y)
INPUT_WIDTH_PX
BLOCK_ELEMENTS
class DocumentLayout:
def __init__(node)
def layout()
def should_paint()
def paint()
class BlockLayout:
def __init__(node, parent, previous)
def layout_mode()
def layout()
def recurse(node)
def new_line()
def word(node, word)
def input(node)
def self_rect()
def should_paint()
def paint()
class LineLayout:
def __init__(node, parent, previous)
def layout()
def should_paint()
def paint()
class TextLayout:
def __init__(node, word, parent, previous)
def layout()
def should_paint()
def paint()
class InputLayout:
def __init__(node, parent, previous)
def layout()
def should_paint()
def paint()
def self_rect()
class DrawText:
def __init__(x1, y1, text, font, color)
def execute(scroll, canvas)
class DrawRect:
def __init__(rect, color)
def execute(scroll, canvas)
class DrawLine:
def __init__(x1, y1, x2, y2, color, thickness)
def execute(scroll, canvas)
class DrawOutline:
def __init__(rect, color, thickness)
def execute(scroll, canvas)
def paint_tree(layout_object, display_list)
EVENT_DISPATCH_JS
RUNTIME_JS
class JSContext:
def __init__(tab)
def run(script, code)
def dispatch_event(type, elt)
def get_handle(elt)
def querySelectorAll(selector_text)
def getAttribute(handle, attr)
def innerHTML_set(handle, s)
SCROLL_STEP
class Tab:
def __init__(tab_height)
def load(url, payload)
def render()
def draw(canvas, offset)
def scrolldown()
def click(x, y)
def go_back()
def submit_form(elt)
def keypress(char)
class Chrome:
def __init__(browser)
def tab_rect(i)
def paint()
def click(x, y)
def keypress(char)
def enter()
def blur()
class Browser:
def __init__()
def draw()
def new_tab(url)
def handle_down(e)
def handle_click(e)
def handle_key(e)
def handle_enter(e)
9-1 Node.children. Add support for the children
property on JavaScript Nodes. Node.children
returns the immediate Element children of a node, as an
array. Text children are not included.The DOM method
childNodes gives access to both elements and text
nodes.
9-2 createElement. The document.createElement
method creates a new element, which can be attached to the
document with the appendChild
and insertBefore
methods on Nodes; unlike innerHTML, there’s no
parsing involved. Implement all three methods.
9-3 removeChild. The removeChild
method on Nodes detaches the provided child and returns it,
bringing that child—and its subtree—back into a detached state.
(It can then be re-attached elsewhere, with
appendChild and insertBefore, or deleted.)
Implement this method. It’s more challenging to implement this one,
because you’ll need to also remove the subtree from the Python side.
9-4 IDs. When an HTML element has an id
attribute, a JavaScript variable pointing to that element is predefined.
So, if a page has a <div id="foo"></div>, then
there’s a variable foo referring to that node.This is standard
behavior. Implement this in your browser. Make sure to
handle the case of nodes being added and removed (such as with
innerHTML).
9-5 Event bubbling. Right now, you can attach a
click handler to a (anchor) elements, but not
to anything else. Fix this. One challenge you’ll face is that when you
click on an element, you also click on all its ancestors. On the web,
this sort of quirk is handled by event
bubbling: when an event is generated on an element, listeners
are run not just on that element but also on its ancestors. Implement
event bubbling, and make sure listeners can call
stopPropagation on the event object to stop bubbling the
event up the tree. Double-check that clicking on links still works, and
make sure preventDefault still successfully prevents clicks
on a link from actually following the link.
9-6 Serializing HTML. Reading from innerHTML
should return a string containing HTML source code. That source code
should reflect the current attributes of the element; for
example:
element.innerHTML = '<span id=foo>Chris was here</span>';
element.id = 'bar';
console.log(element.innerHTML);
// Prints "<span id=bar>Chris was here</span>":Implement this behavior for innerHTML as a getter. Also
implement outerHTML, which differs from
innerHTML in that it contains the element itself, not just
its children.
9-7 Script-added scripts and style sheets. The
innerHTML API could cause <script> or
<link> elements to be added to the document, but
currently our browser does not load them when this happens. Fix this.
Likewise, when a <link> element is removed from the
document, its style sheet should be removed from the global list;
implement that as well.Note that, unlike a style sheet, a removed
<script>’s evaluated code still exists for the
lifetime of the web page. Can you see why it has to be that
way?
Did you find this chapter useful?